Laboratorio de Modelado Seguro y Aprendizaje Inteligente en Sistemas de Ingeniería

Herramientas de IA para ciberseguridad y enfermedades neurodegenerativas
Director y IP: Khalid Malik, Director de Programas de Ciberseguridad, Profesor, División de Computación, CIT
El Laboratorio de Modelado Seguro y Aprendizaje Inteligente en Sistemas de Ingeniería (SMILES) es un grupo interdisciplinario con visión de futuro de profesores y estudiantes investigadores que están adoptando un pensamiento innovador para desarrollar soluciones de vanguardia basadas en IA para algunos de los problemas más urgentes. de nuestro tiempo. La investigación traslacional presentada por el equipo de SMILES tiene un impacto que se extiende más allá de nuestra comunidad con soluciones comercializables en ciberseguridad y atención médica que nos beneficiarán a todos.
La visión audaz del laboratorio SMILES ha identificado necesidades apremiantes y se ha centrado inquebrantablemente en crear y mejorar herramientas de inteligencia artificial para resolverlas. Malik y su equipo han publicado muchos artículos en revistas y conferencias, y continúan construyendo sobre esa base. A través de ricas relaciones con expertos médicos y de la industria, el equipo ha podido satisfacer necesidades muy específicas con soluciones relevantes.
Además del impacto externo de la investigación SMILES, los estudiantes que trabajan en proyectos SMILES están adquiriendo una gran cantidad de experiencias únicas. Están expuestos a lo último en inteligencia artificial y herramientas de ciberseguridad, mientras reciben apoyo constante para practicar un pensamiento ágil y crítico que desbloquee un crecimiento que les cambiará la vida. Con la cuidadosa tutoría de Malik, los estudiantes están capacitados para practicar la perseverancia hacia objetivos tangibles importantes. Estas habilidades y las relaciones que forman durarán toda la vida y los prepararán para un mundo que tiene mucha necesidad de personas creativas que sepan cómo cerrar la brecha entre la investigación y la práctica.
En esta página
- Detector de falsificaciones profundas
- Neuroasistencia
- Filtrado web basado en IA
- Curación automatizada de gráficos de conocimiento
- Educación en ciberseguridad automotriz
Desarrollo de un detector robusto y explicable de amenazas cibernéticas y multimedia falsificadas utilizando inteligencia artificial
Financiado por el Fundación Nacional de Ciencias y Investigación traslacional y comercialización de Michigan


Detector de falsificación profunda (DFD)
Revelar la verdad. encontrar justicia

Laboratorio de Modelado Seguro y Aprendizaje Inteligente en Sistemas de Ingeniería


La desinformación es una preocupación creciente para la sociedad y está impulsada por una nueva arma: los archivos multimedia deepfaked. Toda nuestra vida nos han dicho que creamos lo que vemos con nuestros propios ojos y, por primera vez, ya no podemos confiar en ellos. Los Deepfakes generados por IA han abandonado el ámbito de la ciencia ficción y son una realidad inquietante que exige nuestra atención inmediata.
Un Deepfake es esencialmente un medio que ha sido manipulado o generado completamente por IA para que parezca un artefacto original. Con los recientes desarrollos en las herramientas de IA generativa, las capacidades han crecido hasta el punto en que los humanos ya no pueden detectar una diferencia sin ayuda.
Los multimedia falsos son una amenaza creciente en el escenario global. La desinformación no es una táctica nueva, pero las herramientas actuales son mucho más avanzadas. Un vídeo bien realizado con IA de un líder político o industrial puede difundir narrativas falsas sobre políticas públicas o corporativas y tener un impacto público devastador. Imaginemos un vídeo viral en el que algún jefe de Estado extranjero amenazara con un ataque inminente contra Estados Unidos, pero ese vídeo no se puede distinguir de uno real.
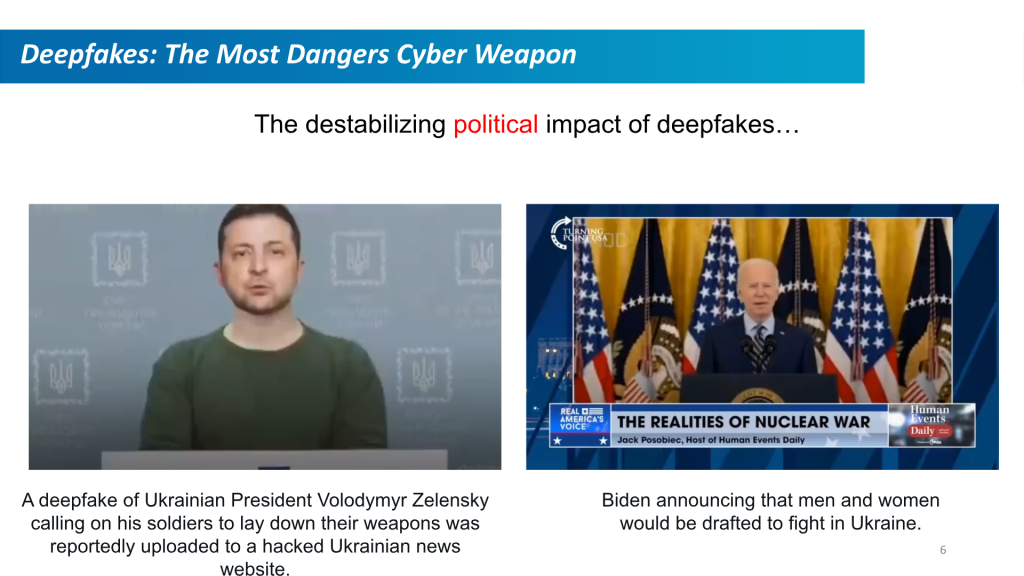
Cada vez es más posible utilizar audio y vídeo deepfake en estafas. El 4 de febrero de 2024, un trabajador financiero de una empresa multinacional fue engañado con una videollamada Deepfake de 'director financiero' y le pagaron. 25 millones de dólares para un estafador.
Si las grandes instituciones financieras pueden ser víctimas de estas cosas, consideremos la vulnerabilidad del ciudadano medio. De acuerdo a un encuesta del 2022 De 16,000 personas en ocho países, el 71% de las personas dijeron que ni siquiera saben qué es un deepfake.
Mientras discutimos la amenaza de los deepfakes a la seguridad global, las instituciones democráticas y las estafas a nivel internacional, es importante señalar que los artefactos de audio y video verificados son ahora la norma como evidencia en nuestro sistema judicial. Los deepfakes representan una amenaza importante para la integridad de ese proceso.
Cumplir con los estándares probatorios judiciales es una tarea desafiante, especialmente en ausencia de metadatos subyacentes, como marcas de agua digitales, o si los medios se procesan posteriormente con intenciones antiforenses. A principios de febrero de 2024, plataformas de redes sociales como Meta anunciaron que exigirán que el contenido generado por IA esté etiquetado como tal, pero eso entra en la categoría de "los candados sólo mantienen fuera a los honestos". Aquellos que tengan la intención de utilizar estas herramientas avanzadas para engañar no les pondrán etiquetas.
A medida que la capacidad de crear videos falsos convincentes ha aumentado significativamente, también ha crecido nuestra necesidad de autenticar artefactos de medios digitales legítimos. Más allá de eso, las herramientas necesarias para autenticar estos artefactos mediáticos deben ofrecer evaluaciones de manera accesible. Nuestro sistema judicial, por ejemplo, está diseñado en torno a un "jurado de pares" que no tendrán un conocimiento profundo de la inteligencia artificial y los sistemas de ciberseguridad.
Para satisfacer esta demanda esencial, hemos desarrollado un detector de falsificación profunda. Esta investigación ha estado en curso durante más de 6 años, respaldada por casi $1 millón en subvenciones de agencias como la Fundación Nacional de Ciencias y MTRAC. Esta financiación nos ha permitido desarrollar el DFD MVP con las herramientas y el conocimiento adecuados y estamos trabajando para desarrollarlos aún más hasta convertirlos en un producto que puedan utilizar empresas e individuos sin una gran experiencia en ciberseguridad.
Los estudiantes investigadores asociados con este proyecto tendrán la oportunidad de aprender a utilizar el aprendizaje profundo, la IA neurosimbólica y la IA multimodal para desarrollar herramientas para autenticar multimedia digital. Los estudiantes también aprenderán cómo proteger los detectores de ataques antiforenses y adquirirán experiencia en el diseño de detectores basados en IA para que sean transparentes y explicables con resultados accesibles. Tendrán la oportunidad de trabajar en equipos interdisciplinarios y resolver problemas más allá de los que encontrarían en un salón de clases.
Esta asociación de NSF para la innovación (NSF-PFI) y el proyecto financiado por MTRAC busca mejorar aún más la tecnología del detector de falsificación profunda (DFD) basada en el premio de linaje NSF n.° 1815724: SaTC: CORE: ForensicExaminer: banco de pruebas para la evaluación comparativa de algoritmos forenses de audio digital y el proyecto MTRAC. titulado "Detector de falsificaciones profundas". El DFD detecta falsificaciones audiovisuales, incluidos varios tipos de Deepfakes, que se utilizan en la manipulación de multimedia digital, pero continuamente aparecen nuevos tipos. Las mejoras al DFD MVP ayudarán a hacerlo más sólido frente a los métodos antiforenses y también a hacerlo más accesible y explicable.
Para más detalles, ver:
- Resumen del premio NSF: ForensicExaminer: banco de pruebas para realizar evaluaciones comparativas de algoritmos forenses de audio digital
- Resumen del premio NSF: Tecnología de detección profunda de falsificaciones
- Comunicado de prensa de MEDC: El centro de innovación MTRAC para informática avanzada da la bienvenida al tercer grupo de proyectos de innovación de tecnología profunda en etapa inicial
NeuroAssist: un sistema inteligente y seguro de apoyo a la toma de decisiones para la predicción de la rotura de un aneurisma cerebral
Financiado por el Fundación de Aneurisma Cerebral
Los accidentes cerebrovasculares, o accidentes cerebrovasculares, son la principal causa de discapacidad en todo el mundo y la segunda causa de muerte. Además, el accidente cerebrovascular es la quinta causa de muerte entre todos los estadounidenses y una de las principales causas de discapacidad grave a largo plazo. Anualmente, 15 millones de personas en todo el mundo sufren un derrame cerebral, y de ellas, 5 millones mueren y otros 5 millones quedan permanentemente discapacitados.
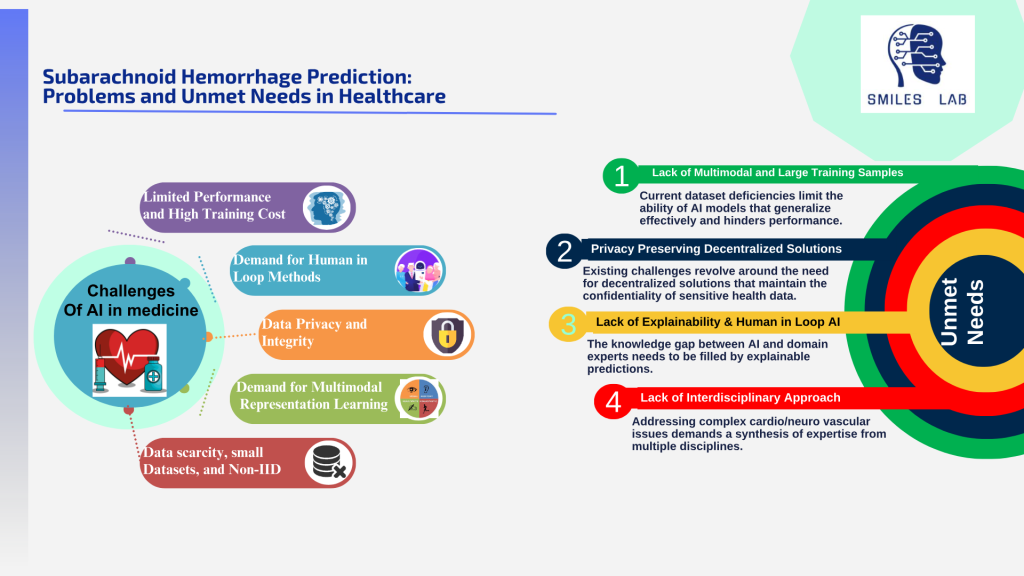
Para prevenir estas muertes y discapacidades, los neurólogos y neurocirujanos deben poder diagnosticar las causas fundamentales de manera temprana y mejorar su manejo clínico. También necesitan determinar el riesgo general de un individuo a través de múltiples consideraciones complejas, incluidos los aneurismas cerebrales, las malformaciones arteriovenosas (MAV) y la enfermedad oclusiva cerebral (COD).
El tratamiento clínico de las enfermedades que causan el ictus es muy complejo. Para ilustrar la complejidad, tomemos el factor de los aneurismas intracraneales no rotos por sí solo. Tratarlos es un proceso de toma de decisiones complejo porque el riesgo de rotura no está determinado únicamente por el tamaño del aneurisma. La ubicación/arteria importa mucho; Los aneurismas pequeños en ciertas arterias pueden romperse, mientras que los más grandes en otras arterias pueden no hacerlo.
Más allá del caso aislado de los aneurismas en sí, diversos grados de malformaciones arteriovenosas y acumulación de placa dentro de las arterias carótidas pueden agregar otros factores de riesgo al riesgo general de accidente cerebrovascular. Nuestras evaluaciones actuales no son suficientes para hacer frente a esta complejidad.
La falta de datos adecuados a menudo conduce a un proceso de toma de decisiones que podría describirse acertadamente como "más vale prevenir que lamentar". Es cierto que la intervención quirúrgica es un método eficaz para eliminar el riesgo de sufrir un accidente cerebrovascular. Sin embargo, estas cirugías son invasivas y pueden provocar complicaciones iatrogénicas graves o déficits neurológicos, por lo que no siempre vale la pena correr el riesgo de tratar todos los aneurismas, MAV y DQO.
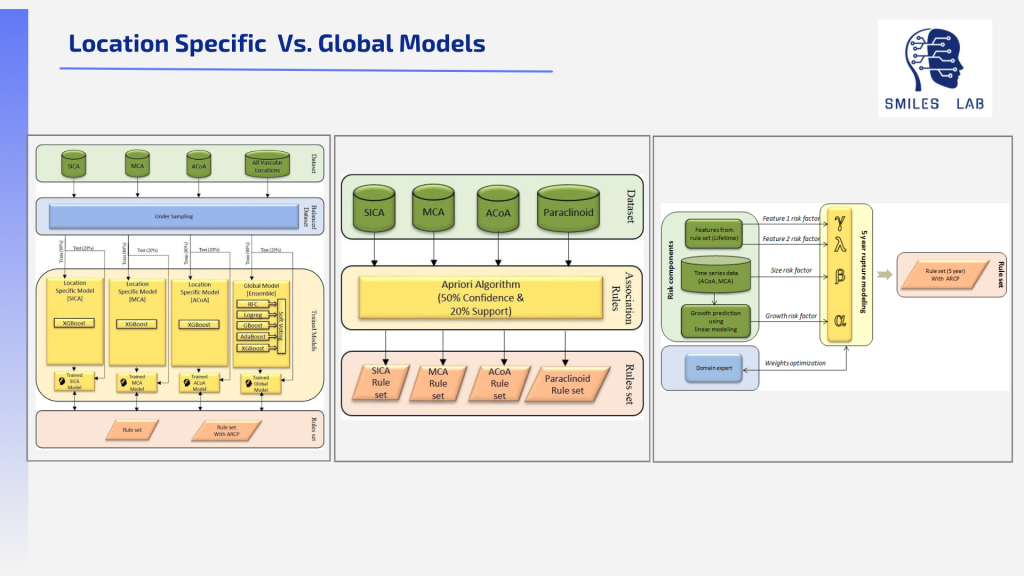
Por otro lado, una intervención tardía cuando se combinan factores aumenta el riesgo de sufrir un derrame cerebral, cuya consecuencia puede ser la muerte o una discapacidad permanente. Cuando el riesgo general es alto, es imperativo realizar el tratamiento correcto de inmediato.
Sin una puntuación clínica fiable de riesgo/gravedad disponible, los neurocirujanos deben confiar en heurísticas compiladas a partir de datos poco fiables y de su experiencia previa.
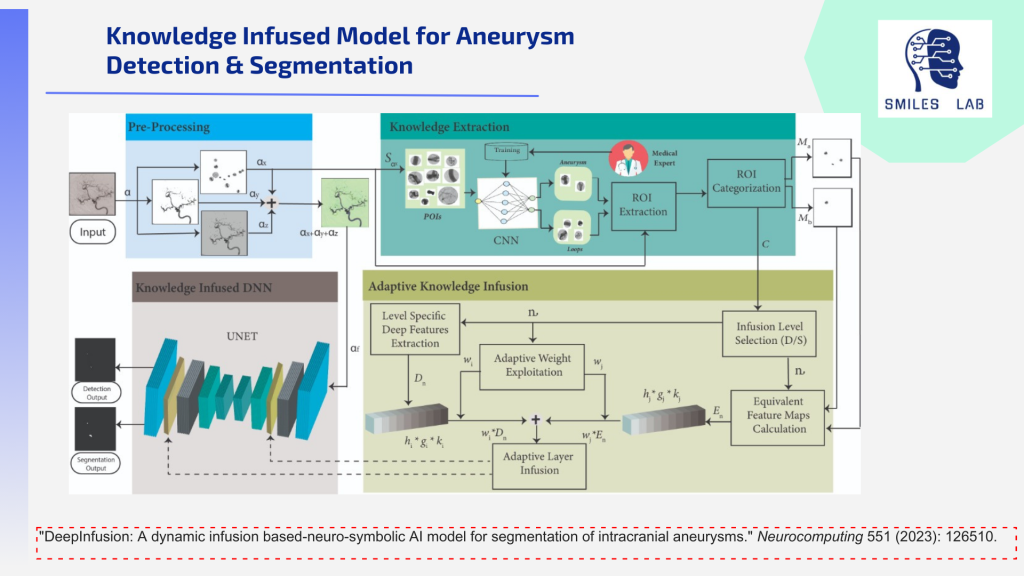
Entre esos dos extremos hay muchos casos en los que el riesgo justifica un seguimiento a lo largo del tiempo, no una acción. Los médicos luchan con la decisión de cuándo tratar y cuándo observar, y cada año se realizan miles de procedimientos innecesarios porque simplemente no es así. seguro. Cuantificar los riesgos generales de accidente cerebrovascular en función de un grupo de factores de riesgo en pacientes similares puede ayudar a que esta decisión crucial sea mucho más fácil para los neurocirujanos.
Esto significa que la herramienta debe ser confiable y que los médicos puedan utilizar para explicar la situación individual. El paciente y la familia se imaginan los peores resultados. Les preocupa un derrame cerebral devastador y la carga financiera del tratamiento. Ser capaz de explicar claramente por qué la mejor opción es esperar y monitorear sería un beneficio maravilloso para esas familias.
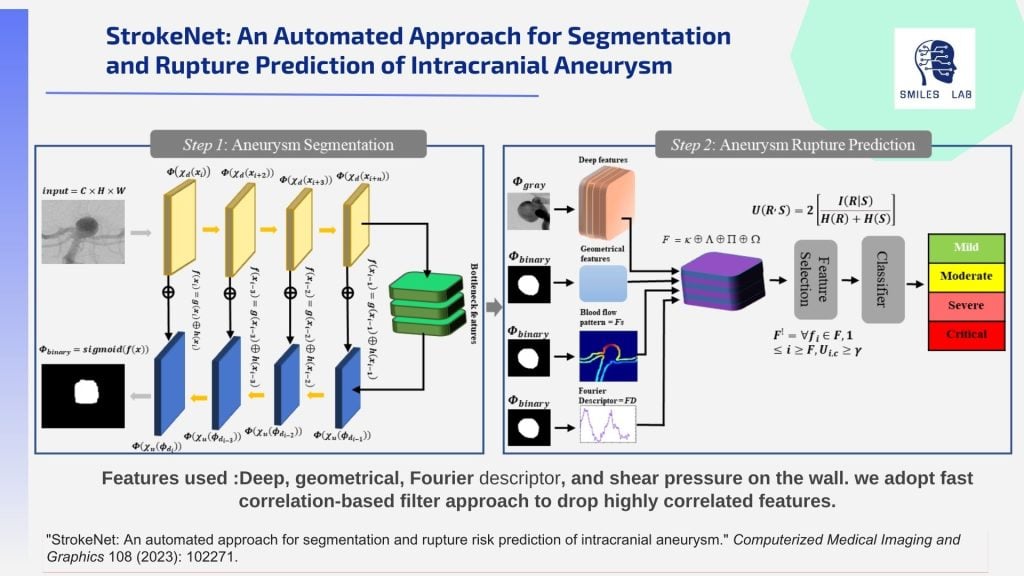
Para satisfacer esta necesidad, hemos desarrollado herramientas con un enfoque basado en IA descentralizado y altamente explicable. Estas herramientas utilizan una amplia gama de técnicas: IA multimodal en angiografía por sustracción digital, angiografía por resonancia magnética y modalidades de imagen de angiografía por tomografía computarizada junto con texto clínico, aprendizaje federado, IA neurosimbólica basada en RAG, dinámica de fluidos computacional e IA explicable multimodal. .
En última instancia, este proyecto brindará herramientas que reducirán las muertes y las discapacidades a largo plazo, sufragarán los altos costos para los pacientes y nuestro sistema de atención médica y aliviarán gran parte del estrés psicológico de los pacientes. También ayudará a desarrollar y compartir datos más sólidos con otros investigadores para avanzar en nuestra comprensión de los aneurismas cerebrales en el futuro.
Para más detalles, ver: Brain Aneurysm Foundation: Conozca al beneficiario de la subvención de investigación: Khalid Malik, PhD
Filtrado web neurosimbólico basado en IA
Patrocinado por Netstar Inc.
Neurosimbólico multimodal explicable
Modelos de Edge AI para filtrado web
Laboratorio de Modelado Seguro y Aprendizaje Inteligente en Sistemas de Ingeniería
Las soluciones de filtrado web son un componente vital de la ciberseguridad. Bloquean el acceso a sitios web maliciosos, evitan que el malware infecte nuestras máquinas y protegen los datos confidenciales para que no salgan de las organizaciones. Ofrecen una experiencia en línea segura, eficiente y controlada en varios sectores, abordando inquietudes relacionadas con la seguridad, la productividad y la idoneidad del contenido. Las crecientes tendencias en el uso de Internet para compartir datos y conocimientos exigen una clasificación dinámica de los contenidos web, particularmente en el borde de Internet.
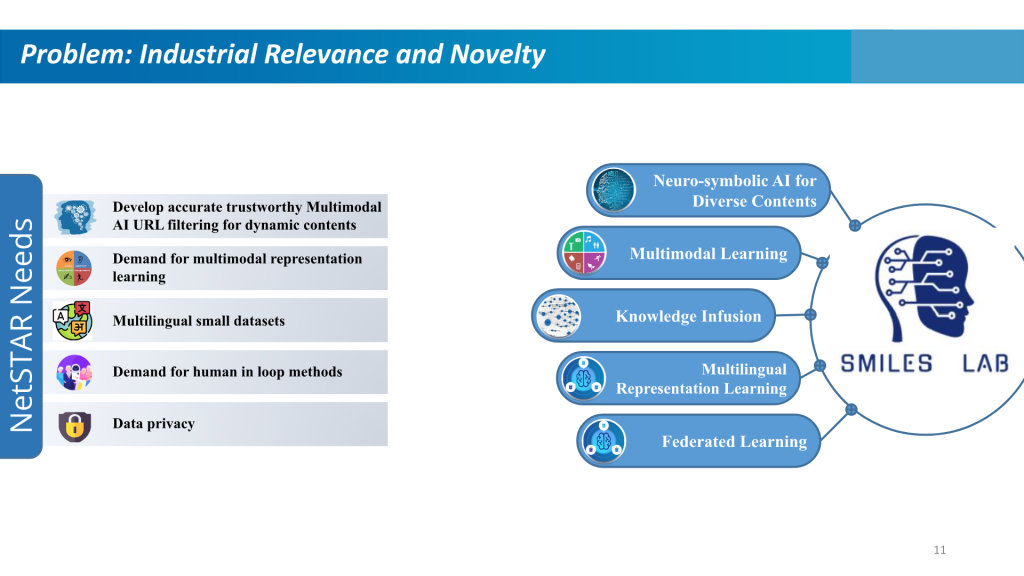
Hoy en día, las empresas necesitan que estas soluciones tengan capacidades multilingües y protejan la privacidad de los datos de sus empleados. Para enfrentar estos desafíos se requiere una solución confiable que pueda clasificar efectivamente las URL en clases correctas.
Para satisfacer estas necesidades, UM-Flint se ha asociado con la empresa japonesa líder en filtrado de URL, Netstar Inc., para desarrollar una solución basada en aprendizaje automático. El equipo está formado por varios estudiantes de doctorado y posdoctorado del laboratorio de modelado seguro y aprendizaje inteligente en sistemas de ingeniería (SMILES) y empleados de Netstar.
Los estudiantes involucrados en este proyecto aprenderán técnicas avanzadas de procesamiento del lenguaje natural, procesamiento de contenido multilingüe y desarrollo de gráficos de conocimiento. Adquirirán experiencia con IA neurosimbólica y multimodal que sea explicable y ofrezca razonamiento. También tendrán oportunidades de adquirir las numerosas habilidades sociales necesarias para colaborar con una corporación global.
Curación automatizada de gráficos de conocimiento neurológico
Para desarrollar sistemas de IA neurosimbólica, es fundamental contar con gráficos de conocimiento que representen todas las entidades de los dominios y las relaciones entre ellas.
El rápido crecimiento de Knowledge Graphs (KG) en los últimos años ha sido indicativo de un resurgimiento de la ingeniería del conocimiento. El uso de KG en la literatura publicada para destilar información utilizable que los modelos neurosimbólicos y los sistemas basados en expertos podrían utilizar es uno de los enfoques más prometedores para el problema del consumo de datos; y además, proporciona más explicaciones sobre técnicas de IA como el aprendizaje automático y el aprendizaje profundo.
Hoy en día, la mayoría de las empresas reconocen que los datos son su activo más valioso, pero pueden presentarse en muchas formas y formatos diferentes. Hacer que esos datos sean utilizables para herramientas de aprendizaje automático e inteligencia artificial es un desafío. Actualmente, la creación y curación de gráficos de conocimiento son en su mayoría manuales o algo semiautomáticas y, por lo tanto, es un proceso que requiere mucha mano de obra. En muchos casos, este proceso manual impide que una persona con un alto nivel de experiencia invierta ese tiempo en el producto principal o en el trabajo científico que podría estar realizando.
La curación automatizada de gráficos de conocimiento a partir de voluminosos datos no estructurados puede extraer información procesable que sea legible por máquina y que potencialmente pueda ayudar a descubrir conocimientos a partir de Big Data. Para obtener información procesable, es necesario identificar fuentes, significados y relaciones entre entidades de los dominios dados.
Además, extraer automáticamente conocimiento confiable y consistente, particularmente de fuentes estructuradas y no estructuradas a escala, es un desafío formidable. Se han realizado muy pocos intentos de construcción automatizada de gráficos de conocimiento en salud. Los que se han probado limitaron su enfoque a la creación de trillizos al tener un solo tipo de relación.
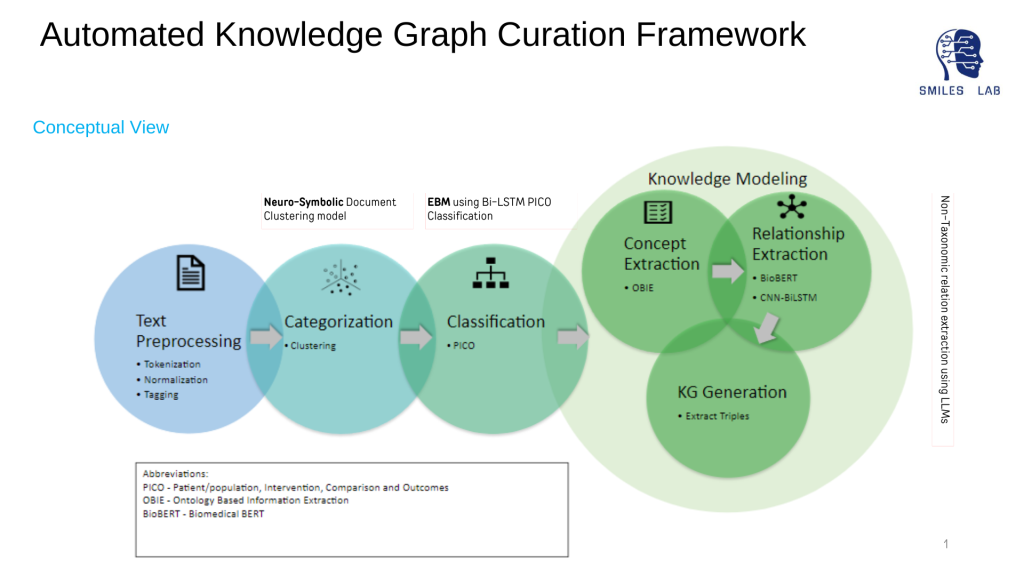
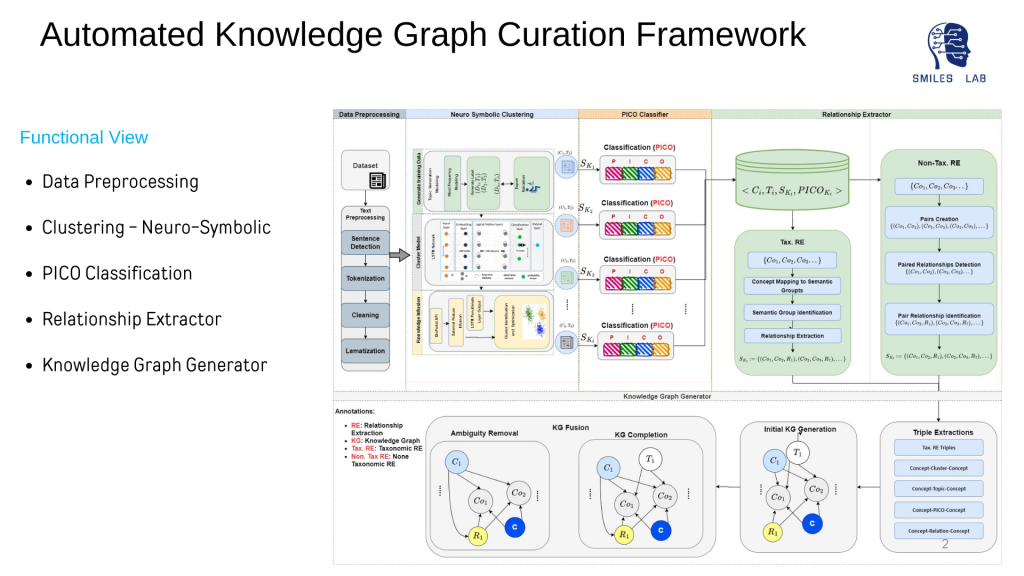
Los modelos tradicionales no consideran las relaciones semánticas, correlativas y causales entre conceptos de dominio en los gráficos de conocimiento. Ninguno de los enfoques existentes se ha centrado en construir relaciones jerárquicas entre conceptos extraídos. Además, la extracción de conceptos mediante incrustación de palabras o extracción de información basada en ontologías no proporciona una precisión confiable y esto también afecta la precisión de la extracción de relaciones. Por último, no se han hecho esfuerzos para desarrollar conocimientos predictivos que deban ser interpretables tanto por máquinas como por humanos para permitir verdaderas interacciones simbióticas entre humanos y máquinas.
Este proyecto intenta resolver los desafíos mencionados anteriormente proponiendo una construcción automatizada de gráficos de conocimiento de dominio específico mediante el uso de datos estructurados y no estructurados. Este proceso se está repitiendo en múltiples industrias en las MVP del detector de deepfake, NeuroasistenciaAIy Filtrado web basado en IA de Netstar proyectos.
Educación en ciberseguridad automotriz
Verificación de integridad del sensor del vehículo
usando gemelo digital e IA multimodal
Laboratorio de Modelado Seguro y Aprendizaje Inteligente en Sistemas de Ingeniería
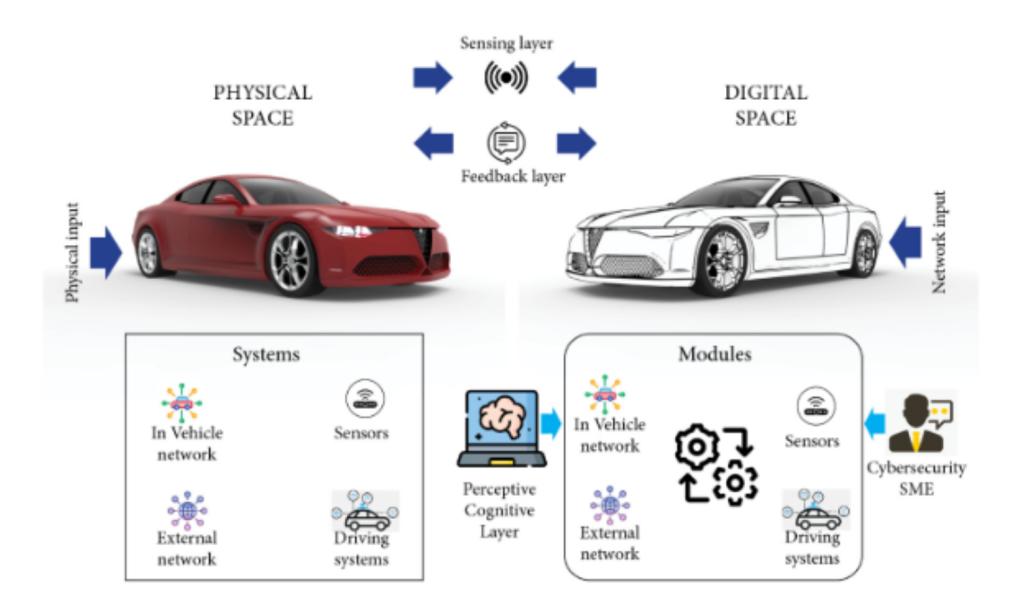
La formación y la contratación en materia de ciberseguridad es uno de los problemas más apremiantes en el desarrollo de la fuerza laboral en la actualidad. Lo global Institución de Ingeniería y Tecnología ha publicado Ciberseguridad automotriz, una revisión de liderazgo intelectual sobre las perspectivas de riesgo para los vehículos conectados, que explica que nuestra trayectoria hacia vehículos más conectados ha aumentado en gran medida la necesidad de profesionales de la ciberseguridad en la industria automotriz.
Sin embargo, cumplir esos roles tiene un desafío: la curva de aprendizaje. La educación en ciberseguridad tal como se imparte hoy en día puede ser un poco árida y teórica, haciéndola parecer más inaccesible de lo que realmente es, pero no tiene por qué ser así.
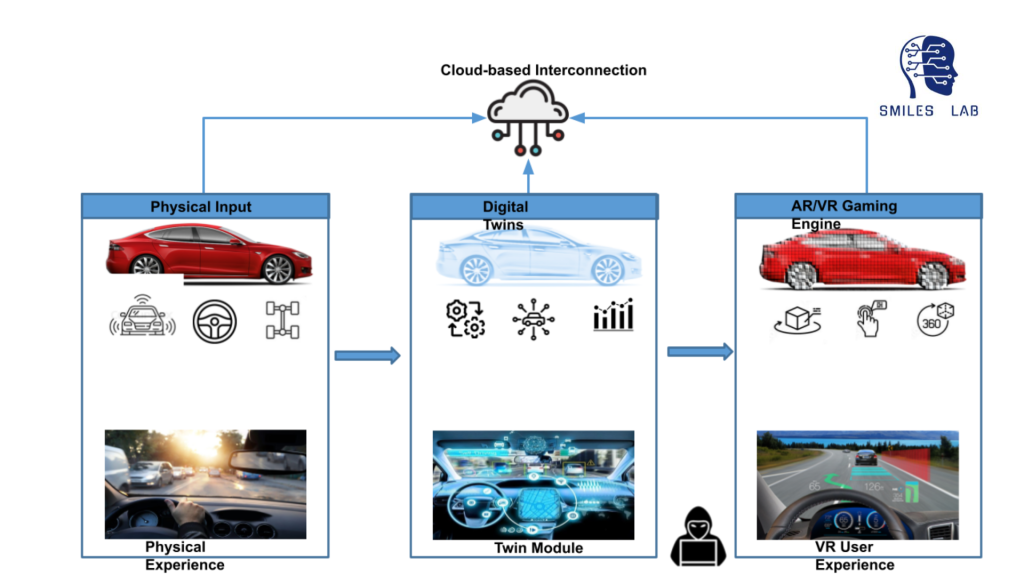
Nuestro grupo de investigación está desarrollando diversas herramientas como 'gemelos digitales' virtuales y un sistema visual de preguntas y respuestas para enseñar la complejidad de temas interdisciplinares como la ciberseguridad en el automóvil. Este proceso permitirá a los estudiantes tener una experiencia de realidad virtual de las formas complejas en que los sensores de IoT, los sistemas de conducción y las redes de sistemas y software dentro y fuera del vehículo interactúan en un vehículo físico.
En resumen, utilizando la lógica neurosimbólica, la inteligencia artificial y el aula invertida, estamos trabajando para rediseñar las clases desde cero, comenzando con una nueva oferta en ciberseguridad automotriz. La clase incluirá ejercicios prácticos sobre el gemelo digital de un sistema de automóvil real y también ofrecerá asistencia las 24 horas del día, los 7 días de la semana con un chatbot basado en un modelo de lenguaje grande como chatGPT.