Modelagem Segura e Aprendizagem Inteligente em Laboratório de Sistemas de Engenharia

Ferramentas de IA para segurança cibernética e doenças neurodegenerativas
Diretor e PI: Khalid Malik, Diretor de Programas de Segurança Cibernética, Professor, Divisão de Computação, CIT
O Laboratório de Modelagem Segura e Aprendizagem Inteligente em Sistemas de Engenharia (SMILES) é um grupo interdisciplinar com visão de futuro de professores e estudantes pesquisadores que estão adotando o pensamento inovador para desenvolver soluções de ponta baseadas em IA para alguns dos problemas mais urgentes Do nosso Tempo. A investigação translacional apresentada pela equipa SMILES tem um impacto que se estende para além da nossa comunidade com soluções comercializáveis em segurança cibernética e cuidados de saúde que irão beneficiar a todos nós.
A visão ousada do laboratório SMILES identificou necessidades urgentes e colocou um foco inabalável na construção e melhoria de ferramentas de IA para resolvê-las. Malik e sua equipe publicaram muitos artigos em periódicos e conferências e estão continuamente construindo sobre essa base. Através de relacionamentos ricos com especialistas médicos e da indústria, a equipe conseguiu atender necessidades muito específicas com soluções relevantes.
Além do impacto externo da pesquisa SMILES, os alunos que trabalham com projetos SMILES estão adquirindo uma riqueza de experiências únicas. Eles são expostos às mais recentes ferramentas de IA e segurança cibernética, ao mesmo tempo em que recebem apoio constante para praticar um pensamento ágil e crítico que desbloqueia um crescimento transformador. Com a orientação atenciosa de Malik, os alunos são capacitados a praticar a persistência em direção a importantes objetivos tangíveis. Estas competências e as relações que elas formam durarão a vida toda e os prepararão para um mundo que tem muita necessidade de indivíduos criativos que saibam como preencher a lacuna entre a pesquisa e a prática.
Nesta página
- Detector de deepfake
- NeuroAssist
- Filtragem da Web baseada em IA
- Curadoria automatizada de gráficos de conhecimento
- Educação em segurança cibernética automotiva
Desenvolvimento de um detector explicável e robusto de multimídia forjada e ameaças cibernéticas usando inteligência artificial
Financiado pela National Science Foundation e Pesquisa e comercialização translacional de Michigan


Detector de falsificação profunda (DFD)
Revele a verdade. Encontre Justiça

Modelagem Segura e Aprendizagem Inteligente em Laboratório de Sistemas de Engenharia
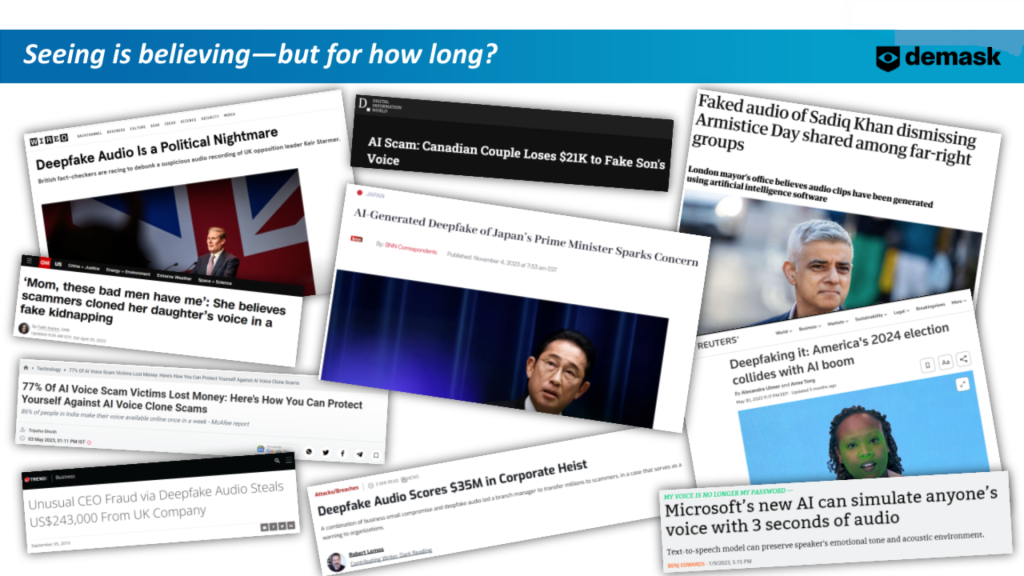


A desinformação é uma preocupação crescente para a sociedade e é alimentada por uma nova arma: a multimédia deepfaked. Durante toda a nossa vida, fomos informados de que deveríamos acreditar no que vemos com nossos próprios olhos e, pela primeira vez, não podemos mais confiar neles. Deepfakes gerados por IA deixaram o reino da ficção científica e são uma realidade perturbadora que exige nossa atenção imediata.
Um Deepfake é essencialmente uma mídia que foi manipulada ou totalmente gerada pela IA para parecer um artefato original. Com os desenvolvimentos recentes nas ferramentas de IA generativa, as capacidades cresceram a tal ponto que os humanos não conseguem mais detectar a diferença sem assistência.
A multimídia falsa é uma ameaça crescente no cenário global. A desinformação não é uma tática nova, mas as ferramentas hoje são muito mais avançadas. Um vídeo de IA bem feito de um líder político ou industrial pode espalhar narrativas falsas sobre políticas públicas ou corporativas e ter um impacto público devastador. Imagine um vídeo viral em que algum chefe de estado estrangeiro ameaça um ataque iminente aos EUA – mas esse vídeo é indistinguível de um vídeo real.
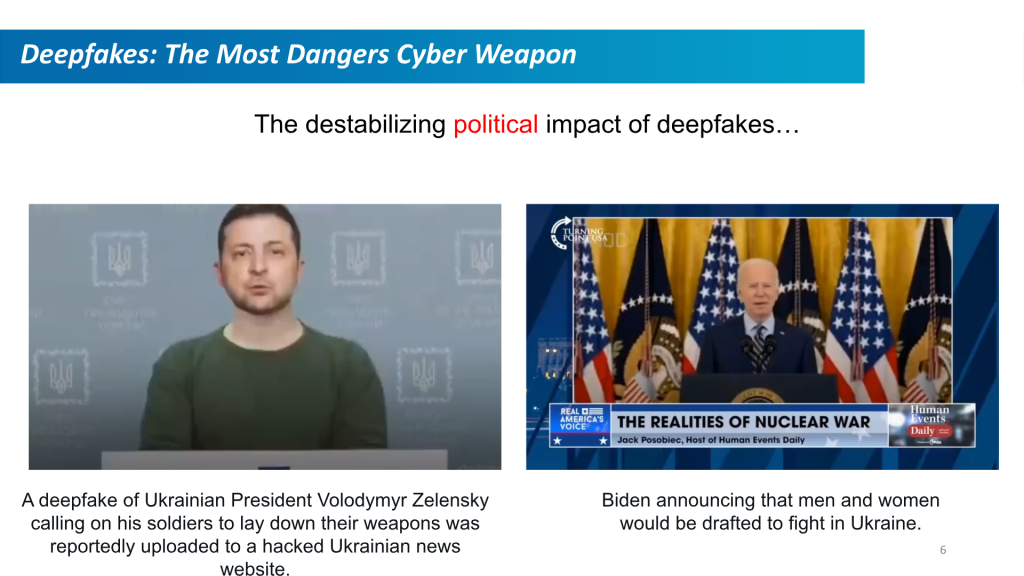
Usar áudio e vídeo deepfaked em golpes é cada vez mais possível. Em 4 de fevereiro de 2024, um funcionário financeiro de uma empresa multinacional foi enganado com uma videochamada Deepfake de 'diretor financeiro' e pago US$ 25 milhões para um golpista.
Se as grandes instituições financeiras podem ser vítimas destas coisas, consideremos a vulnerabilidade do cidadão médio. De acordo com um 2022 pesquisa de 16,000 pessoas em oito países, 71% das pessoas disseram que nem sabem o que é um deepfake.
Enquanto discutimos a ameaça dos deepfakes à segurança global, às instituições democráticas e às fraudes a nível internacional, é importante notar que os artefactos de áudio e vídeo verificados são agora a norma como prova no nosso sistema judicial. Deepfakes representam uma ameaça significativa à integridade desse processo.
Cumprir os padrões probatórios judiciais é uma tarefa desafiadora, especialmente na ausência de metadados subjacentes, como marcas d’água digitais, ou se a mídia for pós-processada com intenção antiforense. No início de fevereiro de 2024, plataformas de mídia social como Meta anunciaram que exigiriam que o conteúdo gerado por IA fosse rotulado como tal, mas isso se enquadra na categoria de “bloqueios apenas impedem a entrada dos honestos”. Aqueles que pretendem usar essas ferramentas avançadas para enganar não colocarão rótulos nelas.
À medida que a capacidade de criar vídeos falsos convincentes aumentou significativamente, a nossa necessidade de autenticar artefactos legítimos de meios digitais também cresceu. Além disso, as ferramentas necessárias para autenticar estes artefactos mediáticos precisam de fornecer avaliações de uma forma acessível. O nosso sistema judicial, por exemplo, é concebido em torno de um “júri de pares” que não terá conhecimentos profundos de IA e de sistemas de segurança cibernética.
Para atender a essa demanda essencial, desenvolvemos um Detector de Falsificação Profunda. Esta pesquisa está em andamento há mais de 6 anos, apoiada por quase US$ 1 milhão em doações de agências como a National Science Foundation e o MTRAC. Este financiamento permitiu-nos desenvolver o DFD MVP com as ferramentas e conhecimentos apropriados e estamos a trabalhar para desenvolvê-los ainda mais num produto que poderá ser utilizado por empresas e indivíduos sem grande experiência em segurança cibernética.
Os estudantes pesquisadores associados a este projeto terão a oportunidade de aprender como usar aprendizagem profunda, IA neurossimbólica e IA multimodal para desenvolver ferramentas para autenticar multimídia digital. Os alunos também aprenderão como proteger detectores contra ataques anti-forenses e ganharão experiência no projeto de detectores baseados em IA para serem transparentes e explicáveis com resultados acessíveis. Eles terão a oportunidade de trabalhar em equipes interdisciplinares e resolver problemas além dos que encontrariam em sala de aula.
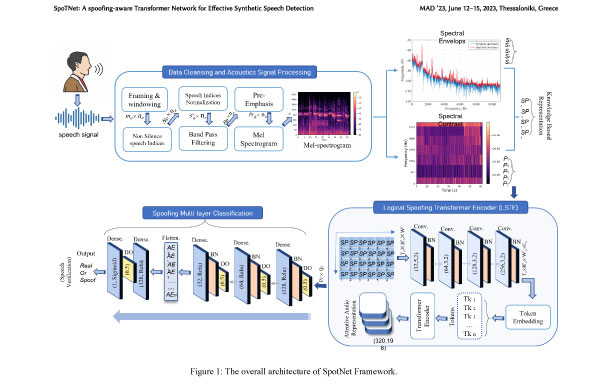
Esta parceria NSF para inovação (NSF-PFI) e projeto financiado pelo MTRAC busca melhorar ainda mais a tecnologia Deep Forgery Detector (DFD) construída no prêmio de linhagem NSF # 1815724: SaTC: CORE: ForensicExaminer: Testbed for Benchmarking Digital Audio Forensic Algorithms e projeto MTRAC intitulado “Detector de falsificação profunda”. O DFD detecta falsificações audiovisuais, incluindo vários tipos de Deepfakes, que são usados na manipulação de multimídia digital, mas novos tipos aparecem continuamente. Melhorias no MVP do DFD ajudarão a torná-lo mais robusto contra análises antiforenses e também a torná-lo mais acessível e explicável.
Para obter detalhes, consulte:
- Resumo do prêmio NSF: ForensicExaminer: Testbed para benchmarking de algoritmos forenses de áudio digital
- Resumo do Prêmio NSF: Tecnologia de Detecção Profunda de Falsificação
- Comunicado de imprensa do MEDC: Centro de inovação MTRAC para computação avançada dá as boas-vindas ao terceiro grupo de projetos de inovação tecnológica profunda em estágio inicial
NeuroAssist: um sistema inteligente e seguro de apoio à decisão para a previsão de ruptura de aneurisma cerebral
Financiado pela Fundação de aneurisma cerebral
O acidente cerebrovascular, ou acidente vascular cerebral, é a principal causa de incapacidade em todo o mundo e a segunda principal causa de morte. Além disso, o acidente vascular cerebral é a quinta principal causa de morte para todos os americanos e uma das principais causas de incapacidade grave a longo prazo. Anualmente, 15 milhões de pessoas em todo o mundo sofrem um acidente vascular cerebral e, destas, 5 milhões morrem e outros 5 milhões ficam permanentemente incapacitados.
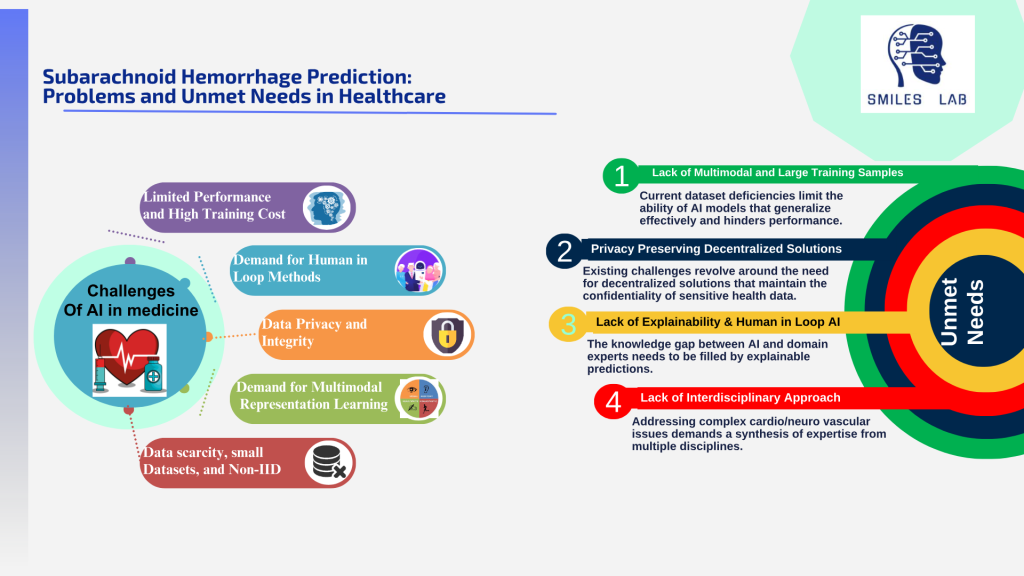
Para prevenir estas mortes e incapacidades, os neurologistas e neurocirurgiões devem ser capazes de diagnosticar precocemente as causas profundas e melhorar o seu tratamento clínico. Eles também precisam determinar o risco geral de um indivíduo em múltiplas considerações complexas, incluindo aneurismas cerebrais, malformações arteriovenosas (MAV) e doença oclusiva cerebral (DCO).
O manejo clínico das doenças que causam acidente vascular cerebral é muito complexo. Para ilustrar a complexidade, consideremos o fator dos Aneurismas Intracranianos Não Rotos por si só. Tratá-los é um processo complexo de tomada de decisão porque o risco de ruptura não é determinado apenas pelo tamanho do aneurisma. A localização/artéria é muito importante; pequenos aneurismas em certas artérias podem romper, enquanto os maiores em outras artérias não.
Além do caso isolado dos próprios aneurismas, vários graus de malformações arteriovenosas e acúmulo de placas dentro das artérias carótidas podem adicionar outros fatores de risco ao risco geral de acidente vascular cerebral. Nossas avaliações atuais não são suficientes para atender a essa complexidade.
A falta de dados adequados muitas vezes leva a um processo de tomada de decisão que poderia ser apropriadamente descrito como “melhor prevenir do que remediar”. É certamente verdade que a intervenção cirúrgica é um método bem sucedido para eliminar o risco de acidente vascular cerebral. No entanto, estas cirurgias são invasivas e podem resultar em complicações iatrogénicas graves ou défices neurológicos, pelo que o tratamento de todos os aneurismas/MAVs/DQO nem sempre compensa esse risco.
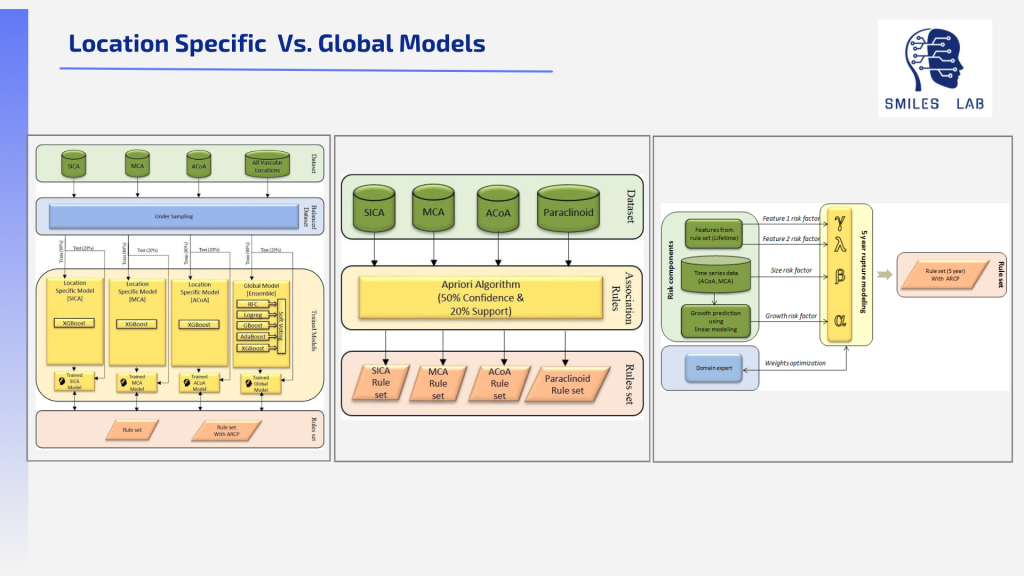
Por outro lado, a intervenção tardia quando a combinação de fatores aumenta o risco de acidente vascular cerebral, a consequência pode ser morte ou incapacidade permanente. Quando o risco geral é alto, é imperativo realizar imediatamente o tratamento correto.
Sem uma pontuação clínica confiável de risco/gravidade disponível, os neurocirurgiões devem confiar em heurísticas compiladas a partir de dados não confiáveis e em sua experiência anterior.
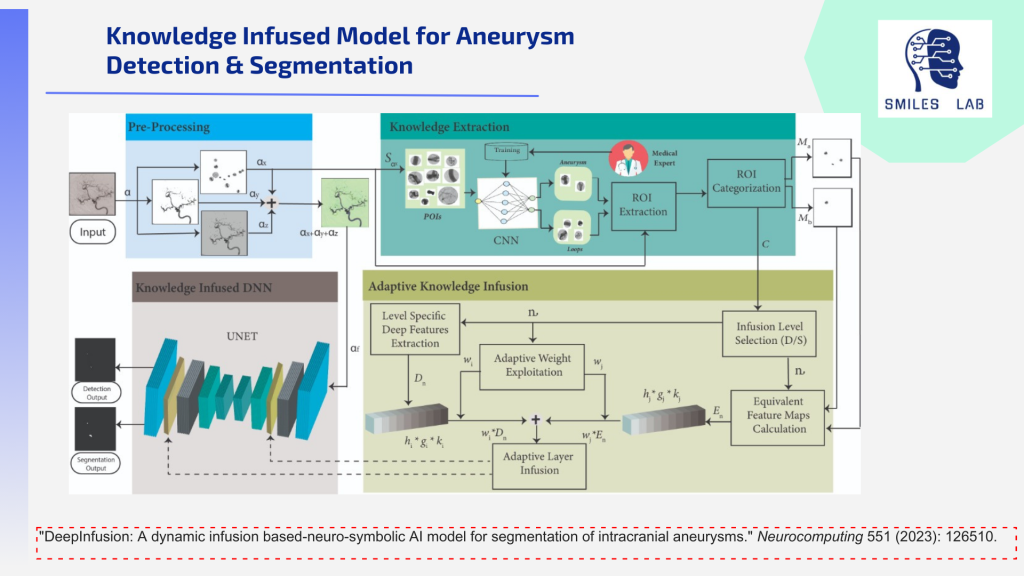
Entre estes dois extremos existem muitos casos em que o risco justifica monitorização ao longo do tempo e não acção. Os médicos lutam para decidir quando tratar e quando observar, e todos os anos milhares de procedimentos desnecessários são realizados porque simplesmente não o são. claro. Quantificar os riscos globais de AVC com base num grupo de factores de risco em pacientes semelhantes pode ajudar a tornar esta decisão crucial muito mais fácil para os neurocirurgiões.
Isso significa que a ferramenta precisa ser confiável e que os médicos possam usar para explicar a situação individual. O paciente e a família estão imaginando os piores resultados. Eles estão preocupados com um acidente vascular cerebral devastador e com o fardo financeiro do tratamento. Ser capaz de explicar claramente por que a melhor opção é esperar e monitorar seria um benefício maravilhoso para essas famílias.
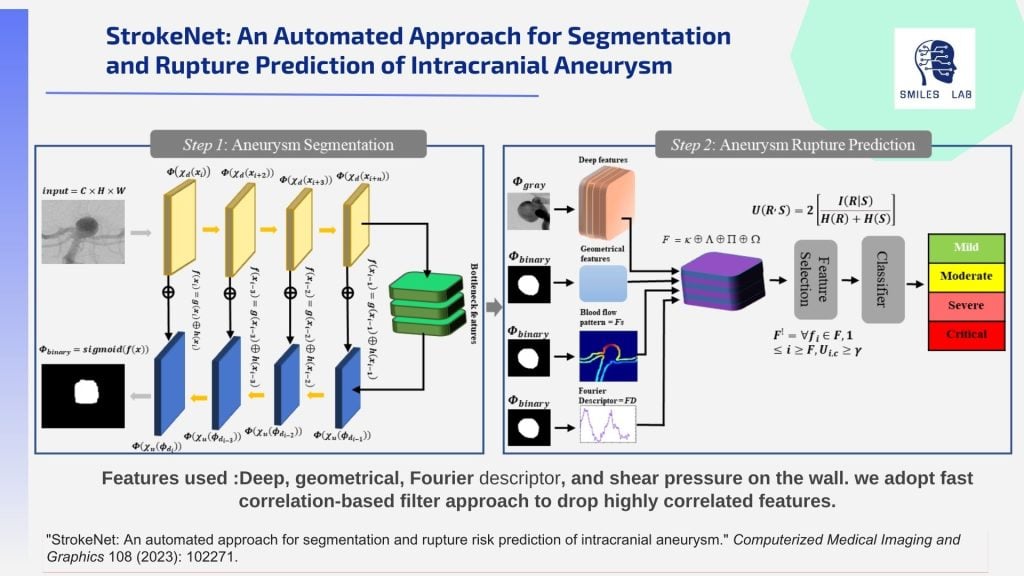
Para atender a essa necessidade, desenvolvemos ferramentas com uma abordagem descentralizada e altamente explicável baseada em IA. Essas ferramentas usam uma ampla gama de técnicas: IA multimodal em angiografia de subtração digital, angiografia por ressonância magnética e modalidades de imagem de angiografia por tomografia computadorizada junto com texto clínico, aprendizagem federada, IA neuro-simbólica baseada em RAG, dinâmica de fluidos computacional e IA explicável multimodal .
Em última análise, este projecto fornecerá ferramentas que reduzirão o número de mortes e incapacidades a longo prazo, custearão custos elevados para os pacientes e para o nosso sistema de saúde e aliviarão muito o stress psicológico dos pacientes. Também ajudará a desenvolver e compartilhar dados mais robustos com outros pesquisadores para avançar na nossa compreensão dos aneurismas cerebrais no futuro.
Para obter detalhes, consulte: Fundação de Aneurisma Cerebral: Conheça o beneficiário da bolsa de pesquisa: Khalid Malik, PhD
Filtragem da Web baseada em IA neuro-simbólica
Patrocinado pela Netstar Inc.
Neurosimbólico multimodal explicável
Modelos Edge AI para filtragem da Web
Modelagem Segura e Aprendizagem Inteligente em Laboratório de Sistemas de Engenharia
As soluções de filtragem da Web são um componente vital da segurança cibernética. Eles bloqueiam o acesso a sites maliciosos, evitam que malware infecte nossas máquinas e protegem dados confidenciais contra saídas das organizações. Eles oferecem uma experiência online segura, eficiente e controlada em vários setores, abordando questões relacionadas à segurança, produtividade e adequação do conteúdo. As tendências crescentes na utilização da Internet para partilha de dados e conhecimentos exigem uma classificação dinâmica dos conteúdos da Web, especialmente na periferia da Internet.
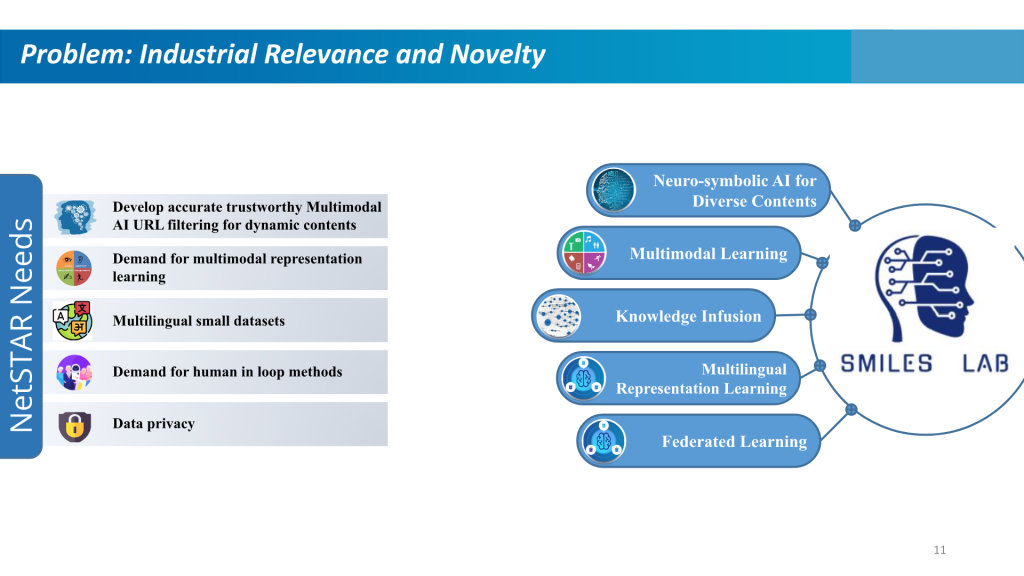
As empresas hoje precisam que estas soluções tenham capacidades multilíngues e protejam a privacidade dos dados dos seus funcionários. Para enfrentar esses desafios, é necessária uma solução confiável que possa classificar efetivamente as URLs nas classes corretas.
Para atender a essas necessidades, a UM-Flint fez parceria com a empresa japonesa líder em filtragem de URL, Netstar Inc., para desenvolver uma solução baseada em aprendizado de máquina. A equipe consiste em vários alunos de doutorado e pós-doutorado do Laboratório de Modelagem Segura e Aprendizagem Inteligente em Sistemas de Engenharia (SMILES) e funcionários da Netstar.
Os alunos envolvidos neste projeto aprenderão técnicas avançadas de Processamento de Linguagem Natural, processamento de conteúdo multilíngue e desenvolvimento de gráficos de conhecimento. Eles ganharão experiência com IA neurossimbólica e multimodal que é explicável e oferece raciocínio. Eles também terão oportunidades de adquirir as muitas habilidades sociais necessárias para a colaboração com uma empresa global.
Curadoria automatizada de gráficos de conhecimento neuro
Para desenvolver sistemas de IA neurossimbólica, é essencial ter gráficos de conhecimento que representem todas as entidades dos domínios e as relações entre elas.
O rápido crescimento dos Gráficos de Conhecimento (KG) nos últimos anos tem sido indicativo de um ressurgimento da engenharia do conhecimento. O uso de KGs na literatura publicada para destilar informações utilizáveis que modelos neurosimbólicos e sistemas baseados em especialistas poderiam usar é uma das abordagens mais promissoras para o problema do consumo de dados; e também fornece mais explicações para técnicas de IA, como aprendizado de máquina e aprendizado profundo
A maioria das empresas reconhece hoje que os dados são o seu ativo mais valioso, mas podem assumir muitas formas e formatos diferentes. Tornar esses dados utilizáveis para ferramentas de ML e IA é um desafio. Atualmente, a criação e curadoria de gráficos de conhecimento são em sua maioria manuais ou semiautomáticas e, portanto, é um processo que exige muito trabalho. Em muitos casos, esse processo manual impede que uma pessoa com alto nível de conhecimento invista esse tempo no produto principal ou no trabalho científico que poderia estar realizando.
A curadoria automatizada de gráficos de conhecimento a partir de dados não estruturados volumosos pode extrair informações acionáveis que são legíveis por máquina e podem potencialmente ajudar na descoberta de conhecimento a partir de Big Data. Para obter informações acionáveis, é necessário identificar fontes, significados e relacionamentos entre entidades de determinados domínios.
Além disso, extrair automaticamente conhecimento confiável e consistente, especialmente de fontes estruturadas e não estruturadas em grande escala, é um desafio formidável. Muito poucas tentativas foram feitas na construção automatizada de gráficos de conhecimento em saúde. Os que foram tentados limitaram seu foco à criação de trigêmeos por terem apenas um tipo de relacionamento.
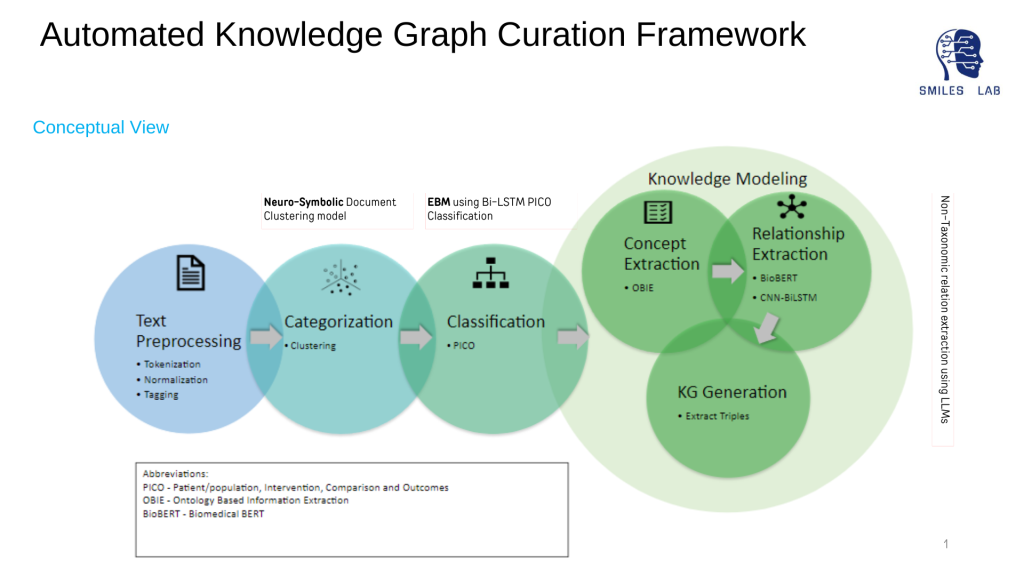
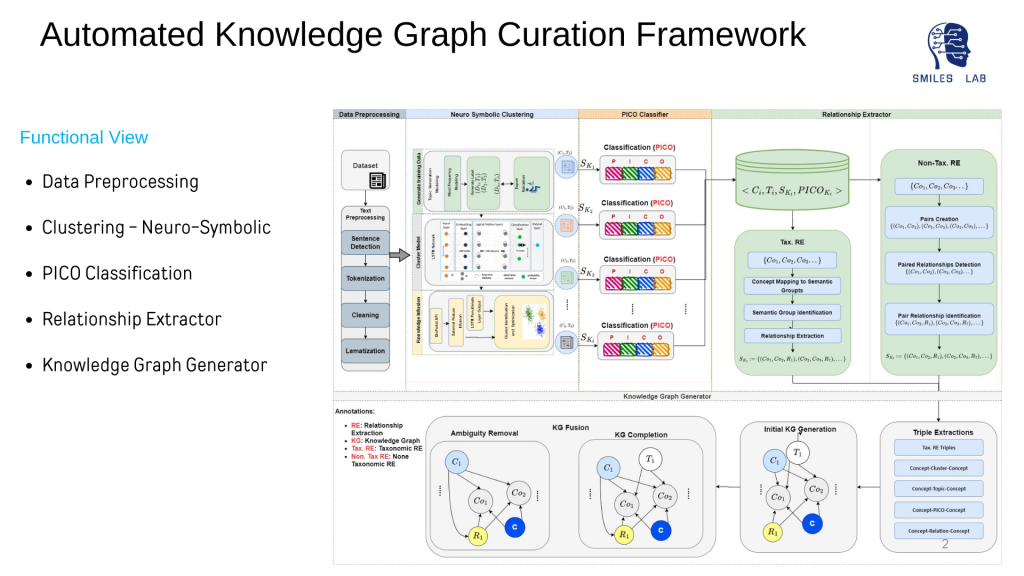
Os modelos tradicionais não consideram relações semânticas, correlativas e causais entre conceitos de domínio em gráficos de conhecimento. Nenhuma das abordagens existentes se concentrou na construção de relações hierárquicas entre os conceitos extraídos. Além disso, a extração de conceitos usando incorporação de palavras ou extração de informações baseadas em ontologias não fornece precisão confiável e isso também afeta a precisão da extração de relacionamento. Por último, não foram feitos esforços para desenvolver conhecimento preditivo que deveria ser interpretável tanto para máquinas como para humanos, para permitir verdadeiras interações simbióticas homem-máquina e máquina-máquina.
Este projeto tenta resolver os desafios acima mencionados, propondo uma construção automatizada de gráfico de conhecimento específico de domínio, fazendo uso de dados estruturados e não estruturados. Este processo está sendo repetido em vários setores em que o MVP do Detector Deepfake, NeuroassistAI e Filtragem da web baseada em IA da Netstar projetos.
Educação em segurança cibernética automotiva
Verificação de integridade do sensor do veículo
usando Gêmeo Digital e IA Multimodal
Modelagem Segura e Aprendizagem Inteligente em Laboratório de Sistemas de Engenharia
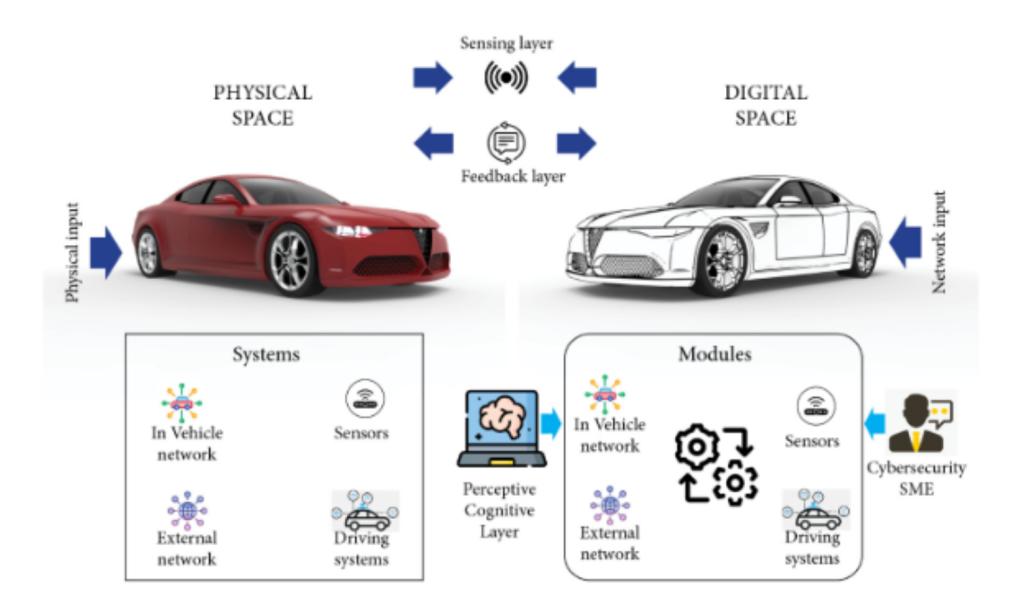
O treinamento e o recrutamento de segurança cibernética são uma das questões mais prementes no desenvolvimento da força de trabalho atualmente. O global Instituição de Engenharia e Tecnologia lançou Segurança cibernética automotiva, uma análise de liderança inovadora sobre as perspectivas de risco para veículos conectados, que explica que a nossa trajetória em direção a veículos mais conectados aumentou enormemente a necessidade de profissionais de segurança cibernética na indústria automotiva.
Porém, preencher essas funções apresenta um desafio: a curva de aprendizado. A educação em cibersegurança tal como é feita hoje pode ser um pouco árida e teórica, fazendo com que pareça mais inacessível do que realmente é, mas não tem de ser assim.
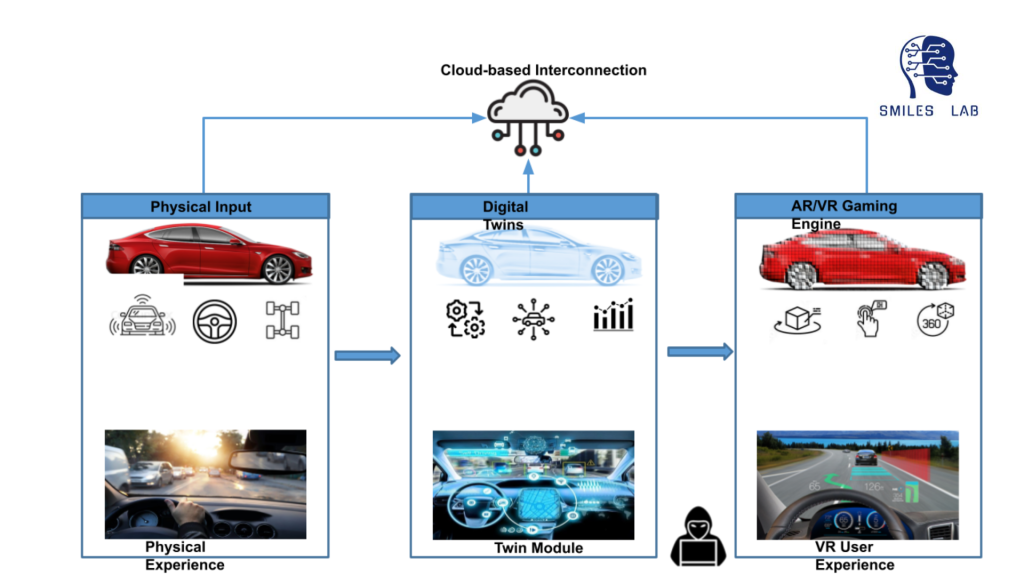
Nosso grupo de pesquisa está desenvolvendo diversas ferramentas, como “gêmeos digitais” virtuais e um sistema visual de perguntas e respostas para ensinar a complexidade de assuntos interdisciplinares, como segurança cibernética em automóveis. Este processo permitirá que os alunos tenham uma experiência de RV das formas complexas como os sensores IoT, os sistemas de direção e as redes de sistemas e software dentro e fora do veículo interagem em um veículo físico.
Em resumo, utilizando a lógica neuro simbólica, a IA e a sala de aula invertida, estamos a trabalhar para redesenhar as aulas desde o início, começando com uma nova oferta em segurança cibernética automóvel. A aula contará com exercícios práticos sobre o gêmeo digital de um sistema automotivo real e também oferecerá assistência 24 horas por dia, 7 dias por semana, com um chatbot baseado em um grande modelo de linguagem como o chatGPT.