工程系统实验室的安全建模和智能学习

用于网络安全和神经退行性疾病的人工智能工具
主任兼PI: 哈立德·马利克, 网络安全项目主任、CIT 计算部教授
工程系统安全建模和智能学习 (SMILES) 实验室是一个由教师和学生研究人员组成的具有前瞻性思维的跨学科小组,他们采用创新思维,针对一些最紧迫的问题开发基于人工智能的尖端解决方案我们这个时代的。 SMILES 团队提出的转化研究的影响超出了我们的社区范围,在网络安全和医疗保健方面提供了适销对路的解决方案,这将使我们所有人受益。
SMILES 实验室的大胆愿景已经确定了紧迫的需求,并坚定不移地专注于构建和改进人工智能工具来解决这些需求。马利克和他的团队发表了许多期刊和会议文章,并在此基础上不断发展。通过与行业和医学专家的丰富关系,该团队能够通过相关解决方案满足非常具体的需求。
除了 SMILES 研究的外部影响之外,参与 SMILES 项目的学生还获得了丰富的独特经验。他们接触最新的人工智能和网络安全工具,同时不断获得支持,练习灵活、批判性的思维,从而实现改变生活的成长。在马利克深思熟虑的指导下,学生们能够坚持不懈地实现重要的切实目标。这些技能和他们形成的关系将是终生的,并为他们做好准备,迎接一个非常需要知道如何弥合研究和实践之间差距的富有创造力的个人的世界。
在本页
使用人工智能开发可解释且强大的伪造多媒体和网络威胁检测器
受资助 美国国家科学基金会 和 密歇根转化研究和商业化


深度伪造检测器 (DFD)
揭示真相。寻求正义

工程系统实验室的安全建模和智能学习
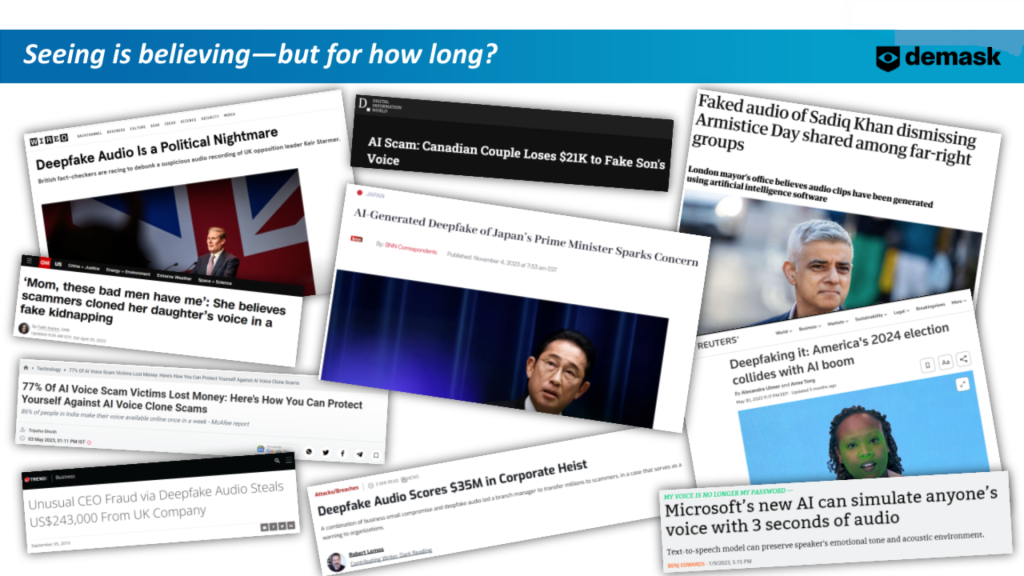


虚假信息日益受到社会关注,而新武器:深度伪造的多媒体更是助长了虚假信息。我们一生都被告知要相信我们亲眼所见,但我们第一次不能再相信他们了。人工智能生成的 Deepfakes 已经脱离了科幻小说的范畴,成为一个令人不安的现实,需要我们立即关注。
Deepfake 本质上是一种由人工智能操纵或完全由人工智能生成的媒体,看起来就像是原始的人工制品。随着生成式人工智能工具的最新发展,这些功能已经发展到人类在没有帮助的情况下无法再检测到差异的程度。
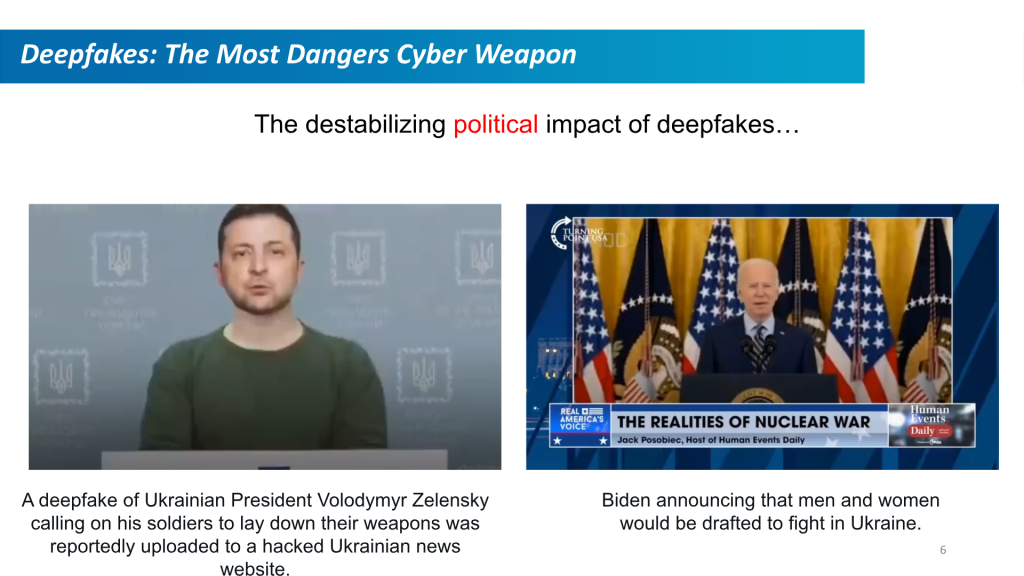
假多媒体是全球舞台上日益严重的威胁。错误信息并不是一种新策略,但当今的工具要先进得多。政治或行业领导者制作精良的人工智能视频可能会传播有关公共或企业政策的虚假叙述,并产生毁灭性的公众影响。想象一下一段病毒视频,其中某位外国国家元首威胁即将对美国发动袭击,但该视频与真实视频没有什么区别。
在诈骗中使用深度伪造的音频和视频的可能性越来越大。 4 年 2024 月 XNUMX 日,一家跨国公司的一名财务人员被 Deepfake“首席财务官”视频通话欺骗并获得报酬 25万美元落入骗子手中.
如果大型金融机构可能成为这些事情的牺牲品,请考虑一下普通公民的脆弱性。根据一个 2022调查 在来自 16,000 个国家的 71 人中,XNUMX% 的人表示他们甚至不知道什么是 Deepfake。
当我们在国际层面上讨论深度造假对全球安全、民主机构和诈骗的威胁时,值得注意的是,经过验证的音频和视频制品现在已成为我们司法系统证据的常态。 Deepfakes 对该过程的完整性构成了重大威胁。
满足法庭证据标准是一项具有挑战性的任务,特别是在缺乏数字水印等基础元数据的情况下,或者媒体经过反取证意图的后处理时。 2024 年 XNUMX 月上旬,Meta 等社交媒体平台宣布,他们将要求人工智能生成的内容被贴上这样的标签,但这属于“锁只会挡住诚实者”的范畴。那些打算使用这些先进工具进行欺骗的人不会给它们贴上标签。
随着创建令人信服的虚假视频的能力显着提高,我们对合法数字媒体工件进行身份验证的需求也随之增长。除此之外,验证这些媒体工件所需的工具需要以可访问的方式提供评估。例如,我们的司法系统是围绕“同行陪审团”设计的,他们对人工智能和网络安全系统没有深入的了解。
为了满足这一基本需求,我们开发了深度伪造探测器。这项研究已经持续了 6 年多,并得到了美国国家科学基金会和 MTRAC 等机构近 1 万美元的资助。这笔资金使我们能够利用适当的工具和知识开发 DFD MVP,我们正在努力将其进一步开发为可供没有网络安全专业背景的公司和个人使用的产品。
与该项目相关的学生研究人员将有机会学习如何使用深度学习、神经符号人工智能和多模态人工智能来开发验证数字多媒体的工具。学生还将学习如何保护探测器免受反取证攻击,并获得设计基于人工智能的探测器的经验,使其透明且可解释并具有可访问的输出。他们将有机会在跨学科团队中工作,解决课堂环境之外的问题。
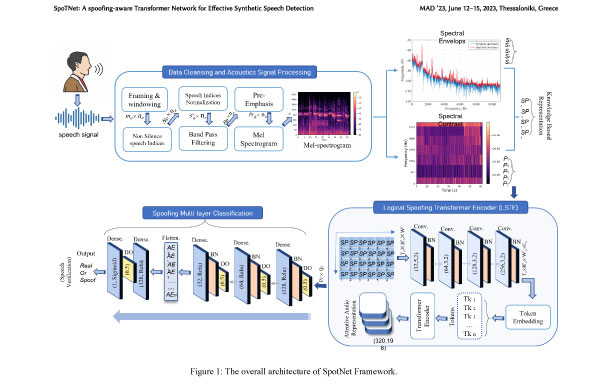
这个 NSF 创新合作伙伴关系 (NSF-PFI) 和 MTRAC 资助的项目旨在进一步改进基于 NSF 血统奖#1815724 的深度伪造检测器 (DFD) 技术:SaTC:CORE:ForensicExaminer:数字音频取证算法和 MTRAC 项目基准测试台标题为“深度伪造探测器”。 DFD 可检测视听伪造,包括用于数字多媒体操作的各种类型的 Deepfakes,但新类型不断出现。 DFD MVP 的改进将有助于使其在反取证方面更加强大,并使其更易于访问和解释。
有关详细信息,请参阅:
NeuroAssist:用于预测脑动脉瘤破裂的智能安全决策支持系统
受资助 脑动脉瘤基金会
脑血管意外或中风是全世界残疾的主要原因,也是死亡的第二大原因。此外,中风是所有美国人的第五大死因,也是严重长期残疾的主要原因。全世界每年有 15 万人遭受中风,其中 5 万人死亡,另有 5 万人永久残疾。
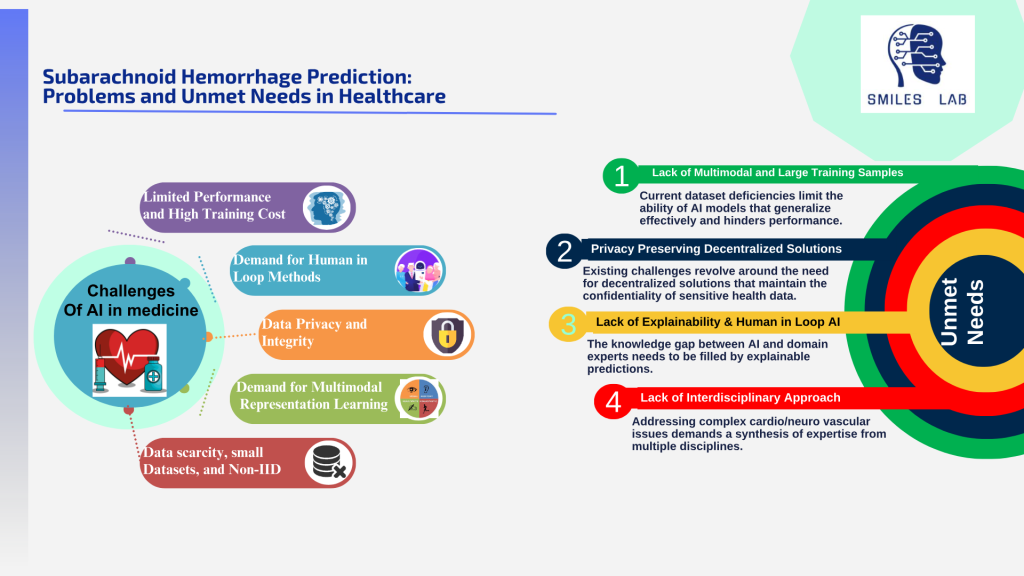
为了防止这些死亡和残疾,神经科医生和神经外科医生必须能够及早诊断根本原因并改善他们的临床管理。他们还需要考虑多种复杂因素来确定个人的总体风险,包括脑动脉瘤、动静脉畸形 (AVM) 和脑闭塞性疾病 (COD)。
引起中风的疾病的临床管理非常复杂。为了说明其复杂性,我们以未破裂颅内动脉瘤本身为例。治疗它们是一个复杂的决策过程,因为破裂的风险不仅仅取决于动脉瘤的大小。位置/动脉非常重要;某些动脉上的小动脉瘤可能会破裂,而其他动脉上的大动脉瘤则可能不会破裂。
除了动脉瘤本身的孤立病例外,颈动脉内不同程度的动静脉畸形和斑块积累也会增加整体中风风险的其他危险因素。我们目前的评估不足以满足这种复杂性。
缺乏正确的数据通常会导致决策过程被恰当地描述为“安全总比后悔好”。毫无疑问,手术干预是消除中风风险的成功方法。然而,这些手术是侵入性的,可能会导致严重的医源性并发症或神经功能缺损,因此治疗所有动脉瘤/AVM/COD 并不总是值得冒这个风险。
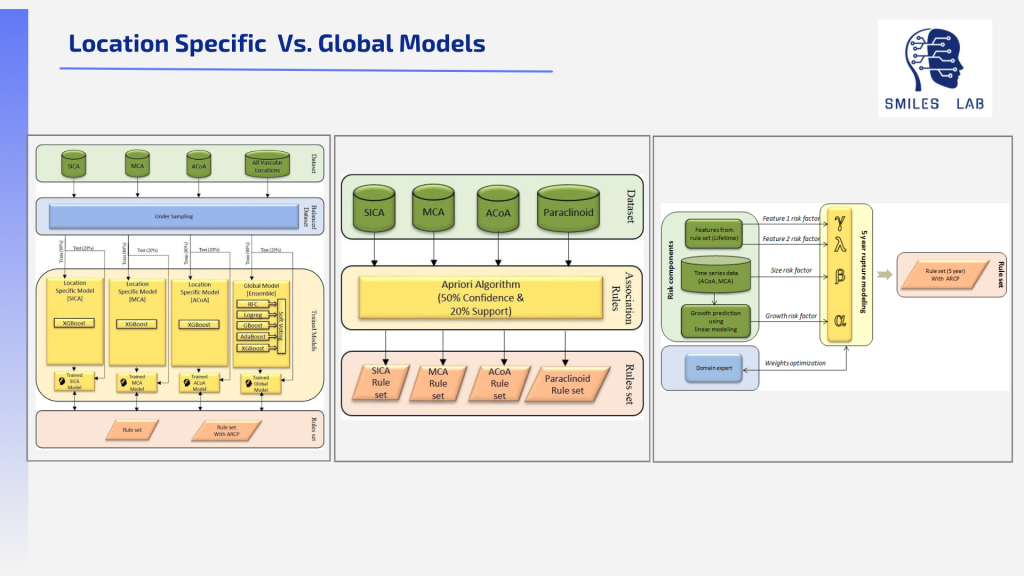
另一方面,综合多种因素时的延迟干预会增加中风的风险,其后果可能是死亡或永久残疾。当总体风险较高时,必须立即进行正确的治疗。
如果没有可靠的临床风险/严重程度评分,神经外科医生必须依靠根据不可靠的数据和以前的经验编制的启发法。
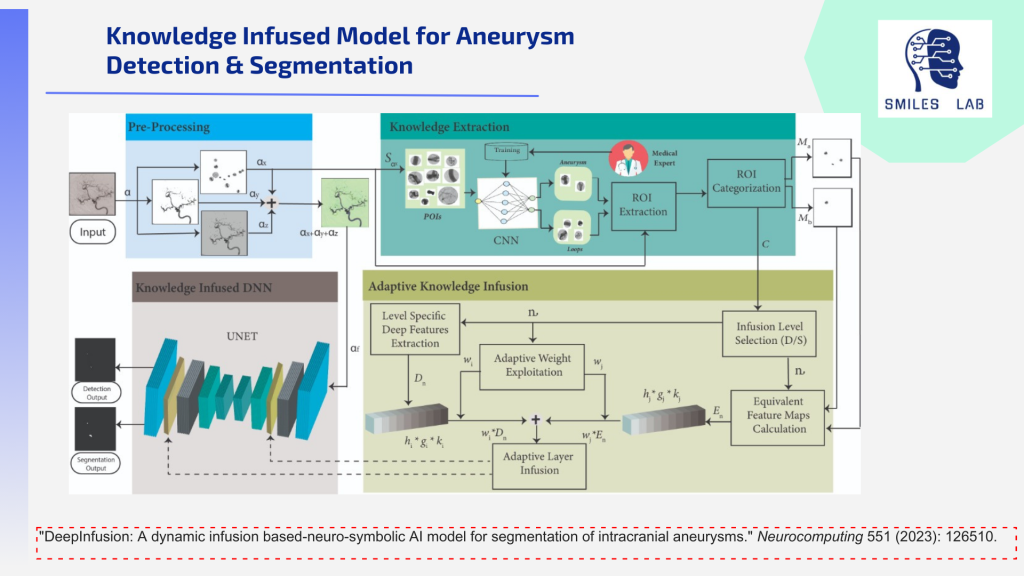
在这两个极端之间,有很多情况需要对风险进行长期监控,而不是采取行动。医生们在决定何时治疗和何时观察方面苦苦挣扎,每年都会进行数以千计的不必要的手术,因为事实并非如此。当然。根据相似患者的一组危险因素量化总体中风风险可以帮助神经外科医生更轻松地做出这一关键决定。
这意味着该工具必须是值得信赖的工具,临床医生可以用它来解释个人情况。患者和家属正在想象最坏的结果。他们担心毁灭性的中风和治疗的经济负担。能够清楚地解释为什么最好的选择是等待和监控,这对这些家庭来说是一个巨大的好处。
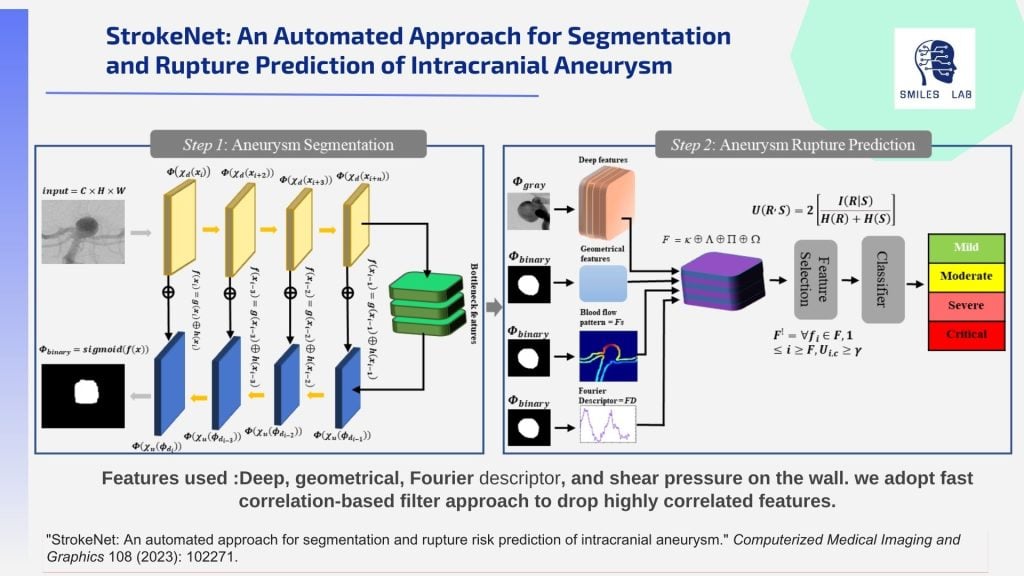
为了满足这一需求,我们开发了采用分散且高度可解释的基于人工智能的方法的工具。这些工具使用多种技术:数字减影血管造影、磁共振血管造影和计算机断层扫描血管造影图像模态的多模态 AI 以及临床文本、联合学习、基于 RAG 的神经符号 AI、计算流体动力学和多模态可解释 AI 。
最终,该项目将提供能够减少死亡和长期残疾的工具,为患者和我们的医疗保健系统支付高昂的费用,并减轻患者的心理压力。它还将有助于开发和与其他研究人员分享更可靠的数据,以增进我们对未来脑动脉瘤的理解。
有关详细信息,请参阅: 脑动脉瘤基金会:会见研究资助者:Khalid Malik 博士
基于神经符号人工智能的网页过滤
主办单位 网星公司
可解释的多模态神经符号
用于网页过滤的边缘人工智能模型
工程系统实验室的安全建模和智能学习
网络过滤解决方案是网络安全的重要组成部分。它们阻止对恶意网站的访问,防止恶意软件感染我们的机器,并保护敏感数据不被泄露到组织之外。它们在各个领域提供安全、高效和受控的在线体验,解决与安全、生产力和内容适当性相关的问题。互联网数据和知识共享使用的不断增长趋势要求对网络内容进行动态分类,特别是在互联网边缘。
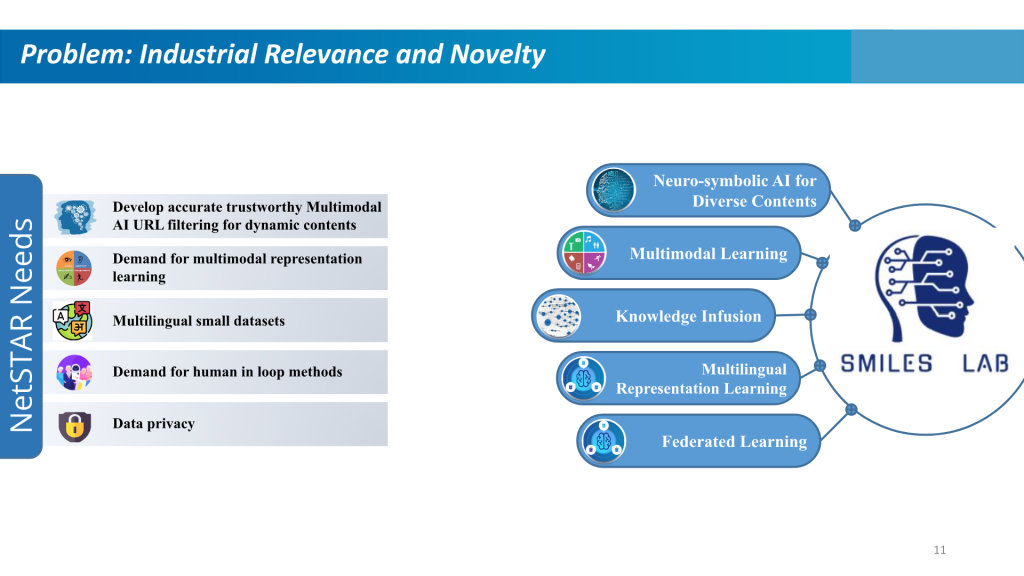
如今的公司需要这些解决方案具有多语言功能并保护员工的数据隐私。为了应对这些挑战,需要一个可靠的解决方案,能够有效地将 URL 分类为正确的类别。
为了满足这些需求,UM-Flint 与日本领先的 URL 过滤公司 Netstar Inc. 合作,开发基于机器学习的解决方案。该团队由工程系统安全建模与智能学习(SMILES)实验室多名博士生和博士后以及网星公司员工组成。
参与该项目的学生将学习自然语言处理、多语言内容处理和知识图开发的先进技术。他们将获得神经符号和多模式人工智能方面的经验,这些人工智能是可解释的并提供推理。他们还将有机会获得与跨国公司合作所需的许多软技能。
自动化神经知识图管理
要开发神经符号人工智能系统,必须拥有代表领域所有实体及其之间关系的知识图。
近年来知识图(KG)的快速增长表明知识工程的复兴。在已发表的文献中使用 KG 来提取神经符号模型和基于专家的系统可以使用的可用信息是解决数据消耗问题最有前途的方法之一;并且对机器学习、深度学习等人工智能技术提供了更多的解释
当今大多数公司都认识到数据是他们最有价值的资产,但它可以有多种不同的形式和格式。让这些数据可用于机器学习和人工智能工具具有挑战性。目前,知识图谱的创建和管理大多是手动或半自动化的,因此这是一个劳动密集型的过程。在许多情况下,这个手动过程会让具有高水平专业知识的人无法将时间投入到他们可以做的核心产品或科学工作上。
从大量非结构化数据中自动管理知识图可以提取机器可读的可操作信息,并可能有助于从大数据中发现知识。为了获得可操作的信息,有必要识别给定域的实体的来源、含义以及之间的关系。
此外,自动提取可靠且一致的知识,特别是从大规模的结构化和非结构化来源中提取知识,是一项艰巨的挑战。关于健康知识图谱的自动化构建的尝试很少。那些已经尝试过的人通过只拥有一种类型的关系将他们的注意力限制在三胞胎的创造上。
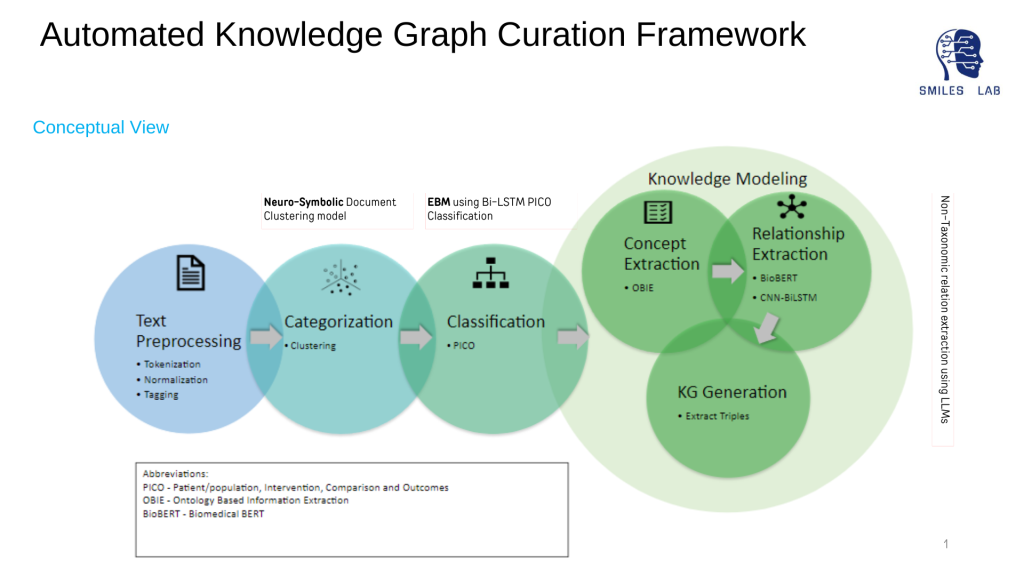
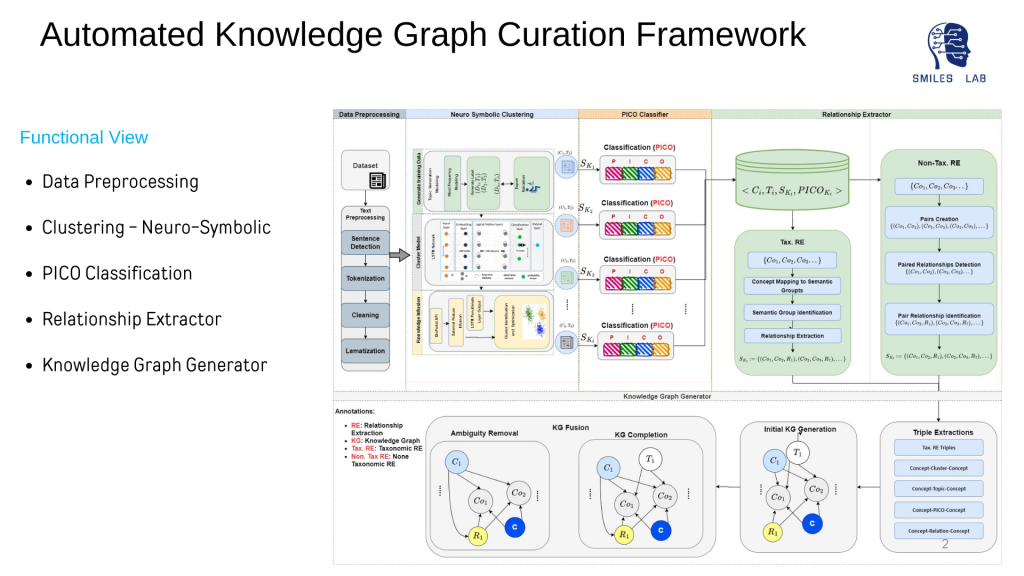
传统模型不考虑知识图谱中领域概念之间的语义、相关性和因果关系。现有的方法都没有专注于在提取的概念之间建立层次关系。此外,使用词嵌入或基于本体的信息提取的概念提取并不能提供可靠的准确性,这也会影响关系提取的准确性。最后,还没有努力开发机器和人类都可以解释的预测知识,以实现真正的共生人机和机器机交互。
该项目试图通过利用结构化和非结构化数据提出自动化的特定领域知识图构建来解决上述挑战。这个过程正在多个行业重复进行 此 Deepfake 检测器 MVP, 神经辅助人工智能及 Netstar 基于人工智能的网页过滤 项目。
汽车网络安全教育
车辆传感器的完整性验证
使用数字孪生和多模式人工智能
工程系统实验室的安全建模和智能学习
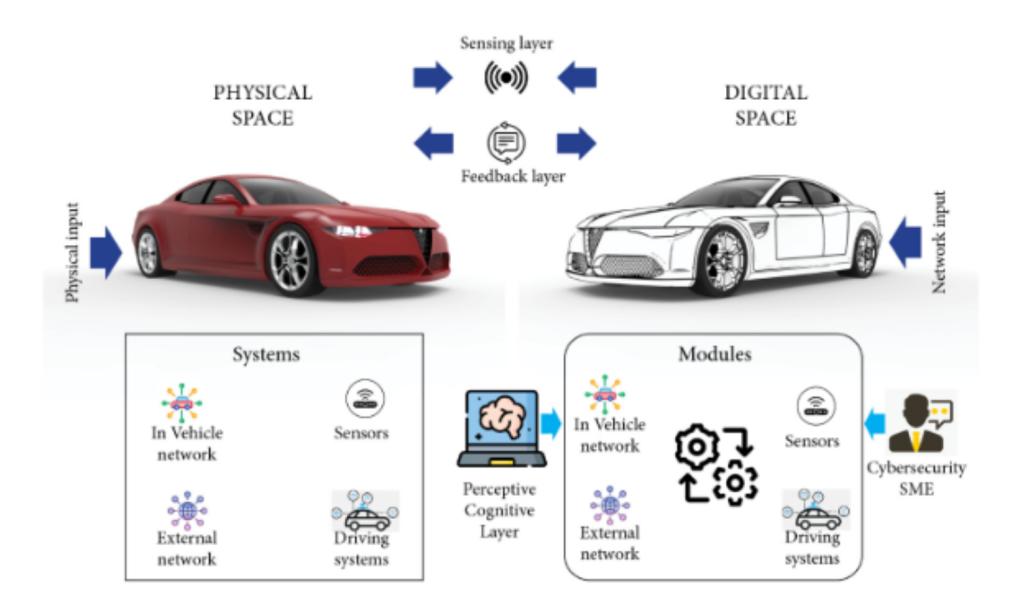
不过,填补这些角色面临着挑战:学习曲线。如今的网络安全教育可能有点枯燥和理论化,使其看起来比实际情况更难以理解,但事实并非必须如此。
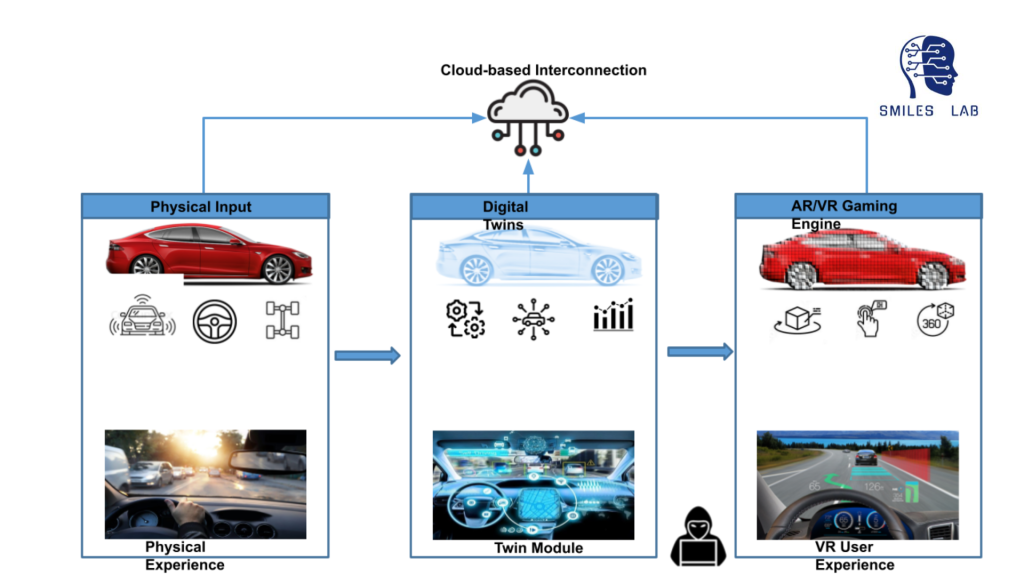
我们的研究小组正在开发各种工具,例如虚拟“数字双胞胎”和视觉问答系统,以教授汽车网络安全等跨学科主题的复杂性。这一过程将使学生能够通过 VR 体验物联网传感器、驾驶系统以及车辆内外的系统和软件网络在物理车辆中交互的复杂方式。
总之,利用神经符号逻辑、人工智能和翻转课堂,我们正在努力从头开始重新设计课程,从汽车网络安全的新产品开始。该课程将以真实汽车系统的数字孪生进行实践练习,并将通过基于大型语言模型(如 chatGPT)的聊天机器人提供 24/7 帮助。